type
status
date
slug
summary
tags
category
icon
password
AI summary
背景
继前面的大字段全量更新(
Full Update)之后,部分更新(Partial Update)它来了。注意,这里说的大字段更新指的都是溢出存储的大字段的更新。inline存储的大字段的更新起来没有什么特别之处,也没有太多可优化的地方。我们先来回顾一下全量更新的做法:
- 会失效掉大字段关联的所有溢出页
- 判断更新后的值是否满足溢出条件
- 如果不满足直接
inline存储 - 如果满足则创建新的溢出页来承载 总之全量更新之后,老的溢出页全部都会失效。
而部分更新指的是,对于一个多页(大于1页)的溢出列的更新,我们可以只更新需要更新的页,其他页不会被失效,可以继续使用。
前置知识点
MySQL 8.0对于Uncompressed LOB的结构改造
前面的文章已经详细介绍过了,这里就不赘述了。
结构改造的主要目的是针对多页的溢出列,可以根据偏移量,快速定位到目标页。因为JSON的部分更新都是以key-value为维度进行更新的,所以根据key、value的偏移量定位到目标位置的性能对整体性能影响非常大。这个相信你继续往下了解了JSON字段的物理存储结构后会有一个更加清晰的理解。
部分更新的条件
使用
Partial Update需满足以下条件:- 被更新的列是JSON类型
- 使用JSON_SET,JSON_REPLACE,JSON_REMOVE进行UPDATE操作
- 输入列和目标列必须是同一列
- 变更前后,JSON文档的空间使用不会增加
JSON类型的存储结构
MySQL提供了一套将JSON字符串转为结构化二进制对象的存储方式,你可以参考源码json_binary.cc和json_binary.h进行学习。
一些重要对象的定义如下:
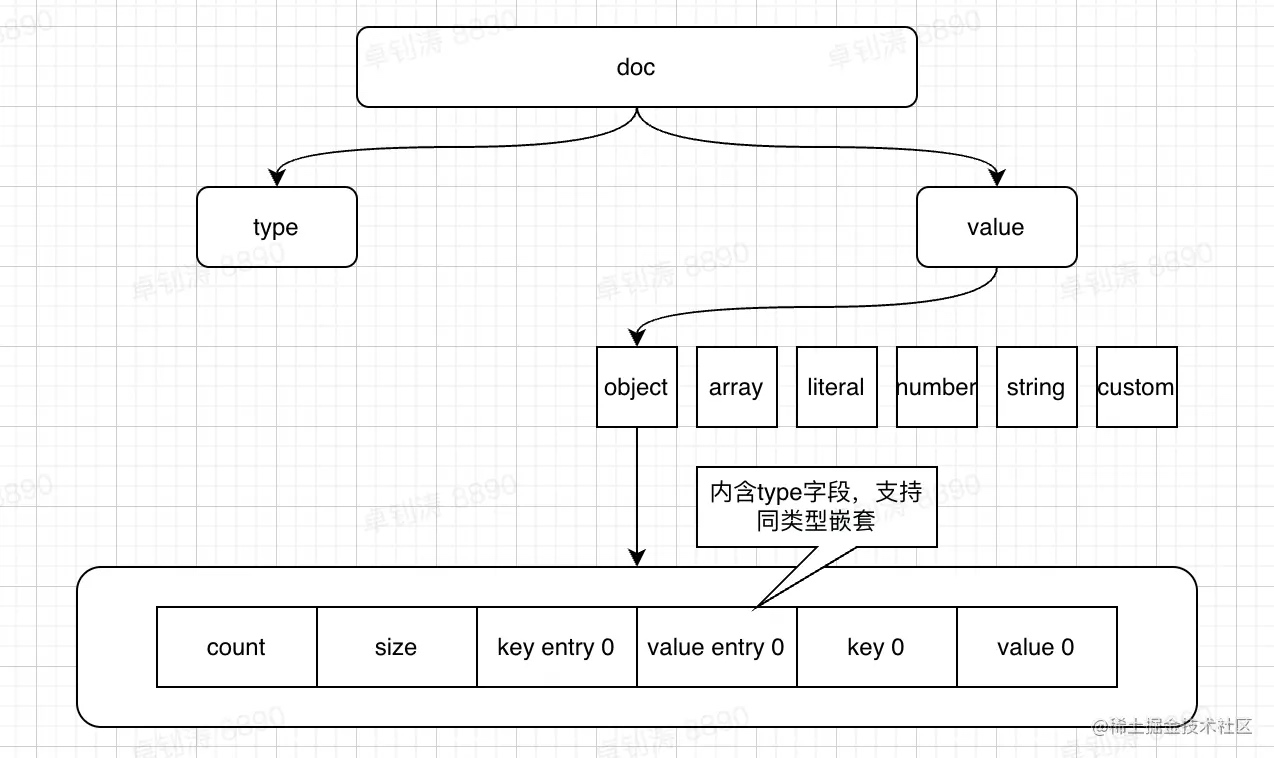
具体的,json会被转为二进制的doc对象存储于磁盘中。doc对象包含两个部分,type和value部分。其中type占1字节,可以表示14种类型:大的和小的json object类型、大的和小的 json array类型、literal类型(true、false、null三个值)、number类型(int6、uint16、int32、uint32、int64、uint64、double类型、utf8mb4 string类型和custom data(mysql自定义类型)。
- value包含 object、array、literal、number、string和custom-data六种类型,与type 14种类型对应。
- size,记录json列的大小,是完整二进制表示去掉开头type字段后的大小
- object表示json对象类型,由6部分组成:object ::= element-count size key-entry* value-entry* key* value*,其中:
- element-count表示对象中包含的成员(key)个数,在array类型中表示数组元素个数。
- size表示整个json对象的二进制占用空间大小。小对象用2Bytes空间表示(最大64K),大对象用4Bytes表示(最大4G)
- key-entry可以理解为一个用于指向真实key值的数组。本身用于二分查找,加速json字段的定位。
- value-entry与key-enter功能类似,不同之处在于,value-entry可能存储真实的value值。
- array表示json数组,array类型主要包含4部分。array ::= element-count size value-entry* value*
- key-entry由两个部分组成:key-entry ::= key-offset key-length,其中:
- key-offset:表示key值存储的偏移量,便于快速定位key的真实值。
- key-length:表示key值的长度,用于分割不同key值的边界。长度为2Bytes,这说明,key值的长度最长不能超过64kb.
- value-entry由两部分组成 value-entry ::= type offset-or-inlined-value,其中:
- type表示value类型,如上文所示,支持14种基本类型,从而可以表示各种类型的嵌套。
- offset-or-inlined-value:有两层含义,如果value值是literal类型或者是足够小的整数类型,可以存储于此,那么就存储数据本身,如果数据本身较大,则存储真实值的偏移用于快速定位。
- key 表示key值的真实值,类型为:key ::= utf8mb4-data,这里无需指定key值长度,因为key-entry中已经声明了key的存储长度。同时,在同一个json对象中,key值的长度总是一样的。
此外还包含一些简单的基本类型,这里不再赘述,需要指出的是,在mysql中json的对象的存储也是层级存储,同时支持类型的嵌套,从value-entry类型的定义就可以看出,因为它包含了一个type字段,该字段和doc中的type是一样的。
下图以json object类型为例,展示了doc的结构
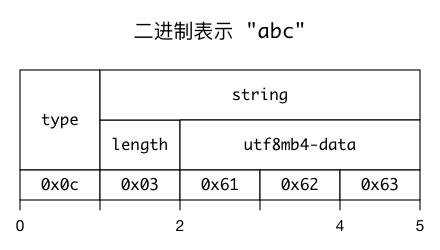
下面我们再以二进制格式展示三种常见类型的结构(string、json object、json array)
string
json array

json object
为了能利用二分搜索快速定位键,存入数据库的JSON对象的键是被排序过的。

doc对象的type只能是json array或者是json object,其余的type主要是用于描述数组元素或者是json object的value
JSON快速定位
上面的结构为JSON的快速定位打好了基础。现在假设我们要更新JSON的某个key-value,我们要做的就是二分查找key-entry,然后根据offset去找对应的key,比较后继续进行二分查找,直到找到对应的key或者二分查找结束。而Mysql 8.0对LOB页结构的调整就是通过增加索引结构来支持offset的快速定位。
找到了key-entry之后,value-entry和它是一一对应的,并且由于key-entry、value-entry、element-count、size都是固定大小并且位置顺序也一致,得到了key-entry就能很方便的计算出value-entry的偏移量,从而得到具体的value。
需要注意,key-offset和value-offset不是相对于0位置而言的,更不是相对于记录offset所处的位置,而是相对于上图的B位置。所以key1的offset是18而不是19
实验
下面的实验,我们需要多次通过idb文件观察json的存储结构。无论inline存储还是溢出存储,json列的物理结构都是一样的。并且由于json是mysql层实现的, 所以字节序是小端 (innodb的基本上都是大端)。
字节序和特定编码有关,只有码元超过1个字节的编码才有可能出现字节序问题,比如utf16、utf32
验证size和offset
直接观察上面ibd文件里json的二进制存储即可,可以看到offset都是相对于起始位置+1
这里记录的size是
0x1a,十进制表示为26,而我们用json_storage_size查看发现存储空间是27,也证实了存储的size不包含type占用的1个字节value的inline存储
可以看到,value在前,key在后,其实value是直接inline在了value-entry里。我们再试一个更大的整数
当整数(uint64)需要8个字节存储的时候,我们发现value不再inline存储。我又试了uint32,发现也不是inline存储的,所以临界点应该就是offset所占用的长度,小json是2个字节。感兴趣的朋友可以测试一下大json下的情况
关于length
key-length
key-length固定用2个字节表示,所以key的最大长度为
2^16=65535。正常情况下这个长度肯定够用了,一般来讲key都是比较短的。value-length
value-length并不是定长的,而是自己设计了一套变长的规则,源码里有相关注释:
每个字节的第一位被设计成了标识位,代表是否还要继续读取,真正的可用位数是7位(0~127),如下所示
单个字节最多表示127,2个字节最多表示
128 * 127 + 127 = 16383,以此类推。我们来看几个数字的表示:
10 -> 0a
128 -> 80 01
32897 -> 81 81 02
未溢出情况下的部分更新
这种情况和常规的varchar字段的更新表现基本一致,唯一不同的是,如果是缩短更新,从数据页上看并不会产生碎片空间,这个碎片空间是由json字段自己来维护的。可以通过JSON_STORAGE_SIZE和JSON_STORAGE_FREE来分别查看json字段的占用空间和碎片空间。
下面我们来做个实验
更新前后,我们来观察一下对应的数据页上的变化:
- 数据页上并没有产生碎片
- 这行数据的json字段的size从
0x9601变成了0x03,0x9601按照前面介绍的规则换算成十进制1 * 128 + 16 + 6 = 150

通过JSON_STORAGE_FREE函数观察到json字段内部产生了148个字节的碎片空间
诶,不应该是147个字节吗?你注意看value-length,原本大于127需要2个字节表示,现在只需要一个字节,这里多释放了1个字节。
我们再尝试更新到和原来一样的大小:

看起来json字段内部管理的空间,先缩短再增长到原来大小这种情况是可以复用原空间的
溢出情况下的部分更新
MySQL 8.0主要是优化了溢出场景下JSON字段的部分更新,所以我们先让json字段溢出,再进行测试。由前面的文章可知,如下的表结构,字段name溢出的临界大小为8102,具体计算过程可见:用几个实验验证char、varchar和text的底层存储
溢出页只有一页
而根据json的存储格式,假设我们只存储一个键值对,算一下value能存多少,由于value的大小肯定超过128个字节,但是不可能大于8102,所以value-length为2
所以value的大小为8087时,会溢出。
溢出的情况下,对于碎片空间的复用和非溢出情况下不一样。好像只能复用前99个字节,达到100个字节后,就无法复用,会copy出一个新的溢出页,再在上面更新。
更新后的数据
再更新到99看看,确实还是在复用的
再更新到100,这个时候发现并没有复用老空间,而是增加了一个新的溢出页,并且内容看起来是从老的溢出页复制出来的,然后再在上面做更新,不知道为什么从100这个大小开始就没有办法复用原空间了,希望知道的朋友可以不吝赐教
溢出页有多页
部分更新要在多溢出页的情况下才能发挥其优势,并且json的key-value至少要有两个,因为我们想要只更新某个value所在的那些页。下面我们构建一个有2个溢出页的数据。根据前面的文章我们知道,溢出页首页可以存储的数据容量为15680。如果你想了解计算过程,可以阅读这篇文章——用几个实验验证char、varchar和text的底层存储
假设我们使用两个key-value,并且让json的元数据以及第一个value-length和value填满first page,那么第一个value的长度的计算公式如下:
然后我们再让第二个key-value填满第二个page,第二页的数据容量为16327,减去2个字节的value-length,那么第二个value的长度为16325。我们将记录插入表,并通过观察ibd文件验证符合预期
下面我们更新字段b的value,并且需要满足部分更新的4个条件
先看一下first page,因为有两个溢出页,所以也会有两个index entry,一开始用的就是前两个entry。而这次更新的是字段b,位于第二个溢出页,所以第二个溢出页会失效,并copy出第三个溢出页。第二个index entry也同样会失效,并创建出第三个index entry。

再看一下聚簇索引,上面保存的version信息也有更新

而整个LOB列的读取过程为:
- 先从聚簇索引中找出溢出页首页编号以及LOB版本号
- 读取溢出页首页,找到version匹配的index entry
- 如果version不匹配,则不能读取,要从这个不匹配的index entry的versions版本列表里读取匹配的版本。versions里存了历史版本列表。 整个过程只用到了聚簇索引页里保存的版本、index entry里的版本。
偏移量 | 字节数 | 描述 |
OFFSET_PREV | 6 | Pointer to the previous index entry |
OFFSET_NEXT | 6 | Pointer to the next index entry |
OFFSET_VERSIONS | 16 | Pointer to the list of old versions for this index entry |
OFFSET_TRXID | 6 | The creator transaction identifier. |
OFFSET_TRXID_MODIFIER | 6 | The modifier transaction identifier |
OFFSET_TRX_UNDO_NO | 4 | the undo number of creator transaction. |
OFFSET_TRX_UNDO_NO_MODIFIER | 4 | The undo number of modifier transaction. |
OFFSET_PAGE_NO | 4 | The page number of LOB data page |
OFFSET_DATA_LEN | 4 | The amount of LOB data it contains in bytes. |
OFFSET_LOB_VERSION | 4 | The LOB version number to which this index entry belongs. |
上面这个场景里,可以看到versions为空,我们可以在修改之前,开启另外一个事务读取name的值,这样就能看到versions了。下面就是version为1的index entry,可以看到它就指向原来的9c这个index entry

json_set和普通修改的区别
普通修改后,直接从溢出页变成不溢出了
如果更新成需要溢出的情况,那么会创建一个新的溢出页来保存
这种普通修改不可能走到部分更新,也就是没法基于原来的溢出页修改
binlog 中开启 Partial Updates
Partial Updates 不仅仅适用于存储引擎层,还可用于主从复制场景。
主从复制开启 Partial Updates,只需将参数 binlog_row_value_options(默认为空)设置为 PARTIAL_JSON。
下面具体来看看,同一个 UPDATE 操作,开启和不开启 Partial Updates,在 binlog 中的记录有何区别。
不开启
开启
对比 binlog 的内容,可以看到,不开启,无论是修改前的镜像(before_image)还是修改后的镜像(after_image),记录的都是完整文档。而开启后,对于修改后的镜像,记录的是命令,而不是完整文档,这样可节省近一半的空间。
在将
binlog_row_value_options设置为PARTIAL_JSON后,对于可使用Partial Updates的操作,在binlog中,不再通过ROWS_EVENT来记录,而是新增了一个PARTIAL_UPDATE_ROWS_EVENT的事件类型。需要注意的是,binlog 中使用
Partial Updates,只需满足存储引擎层使用Partial Updates的前三个条件,无需考虑变更前后,JSON文档的空间使用是否会增加。参考
- Author:黑微狗
- URL:https://blog.hwgzhu.com/article/mysql-json-partial-update-test
- Copyright:All articles in this blog, except for special statements, adopt BY-NC-SA agreement. Please indicate the source!