type
status
date
slug
summary
tags
category
icon
password
AI summary
背景
采用批量化的操作来提升性能是一个很常规的思想,一般用于round trip开销比较大的场景。比如调用远程服务,操作数据库,发送MQ消息等等。其实除了减少了round trip的开销之外,批量化操作还提高了请求的利用率,因为每个请求一般都会携带一些”头“数据,比如tcp协议头、http协议头等等,通过批量操作这些头可能就从1000个减少到了1个。
今天我们主要聊聊数据库层面支持哪些批量操作以及它们的特点。
multi-value insert
这是我们最常使用的数据库批量操作的场景。之前还写过两篇文章介绍mybatis的批量插入引起的内存溢出以及解决方案,感兴趣的同学可以点击对应链接阅读。
这里的批量插入语句我们都是使用
mybatis-generator配合com.itfsw:mybatis-generator-plugins插件生成出来的。生成出来的内容大致如下,支持全字段插入和selective插入:batchUpdate
batchUpdate一般分为两种场景:
- 批量更新的内容完全一致
- 批量更新的内容不一致
对于场景1,就是常规的SQL,控制好对应的where条件即可,比如
而对于场景2,就没办法使用一条SQL语句来更新了。我们需要借助:
- MyBatis的动态sql能力
- 开启mysql-connector上的
allowMultiQueries参数,允许一次性执行多条语句
batchDelete
批量场景也比较单一,一般来说控制好where条件就可以了
batchExecute
batchExecute和上面列的三种不属于同一个维度。batchExecute是jdbc规范里定义的一种执行模式——批量执行模式,各个驱动都要去实现这个标准。使用方式如下:先通过
addBatch把单个sql添加到待执行列表里,然后再通过executeBatch一次性批量执行。而最终执行的时候mysql-connector会把每条sql都用;拼接在一起。其实和一条手动用;拼接好的sql直接去执行的效果没有太大的区别。PreparedStatement
如果使用的是
PreparedStatement,那么只有配置了rewriteBatchedStatements=true才能有上面说的效果,否则虽然调用的是addBatch和executeBatch,但是最后执行的时候还是一条条语句发送。Statement
而如果使用的是普通的
Statement,通过配置rewriteBatchedStatements=true或者allowMultiQueries=true 都可以起到批量的效果。batch模式下的SQL优化
在batch模式下,如果你使用的是
PreparedStatement,并且配置了rewriteBatchedStatements=true,驱动还会优化我们的语句。比如:insert优化
会被优化成
需要注意的是,insert语句的改写,只能将多个values后的值拼接成一整条SQL,insert语句如果有其他差异将无法被改写。例如:
上述 insert 语句将无法被改写成一条语句。该例子中,如果将SQL改写成如下形式:
即可满足改写条件,最终被改写成:
update优化
PreparedStatement 的批量更新时如果超过3条更新语句,则SQL语句会改写为multiple-queries的形式并发送,例如:而普通的
Statement ,只要配置了allowMultiQueries=true 或者是配置了rewriteBatchedStatements=true 并且批量更新时如果超过4条更新语句,那么批量更新无论多少条语句都会改写成multiple-queries的形式发送。注意:如果你配置了
allowMultiQueries=false&rewriteBatchedStatements=true,那么ClientPreparedStatement会在执行过程中再发送一条set allowMultiQueries=true的命令。所以尽量不要这样配置,会增加一次IO。batch模式下的ServerPreparedStatement
如果你不了解
ClientPreparedStatement和ServerPreparedStatement,可以看我之前的文章。在不同的PreparedStatement模式下,batch模式的表现也不一样。ClientPreparedStatement和之前介绍的基本一样,而ServerPreparedStatement则有一些区别:在batch模式下,
ServerPreparedStatement会发送两次Prepare命令,第一次是在调用prepareStatement时。第二次是在调用executeBatch时,需要预编译拼接后的SQL。即使两次的内容是一样的,并且开启了cachePrepStmts,也需要调用两次,因为cachePrepStmts并不作用于此(它作用在Connection上,控制需不需要创建PreparedStatement)ServerPreparedStatement 执行过程的抓包信息(两次Prepare)如下图所示: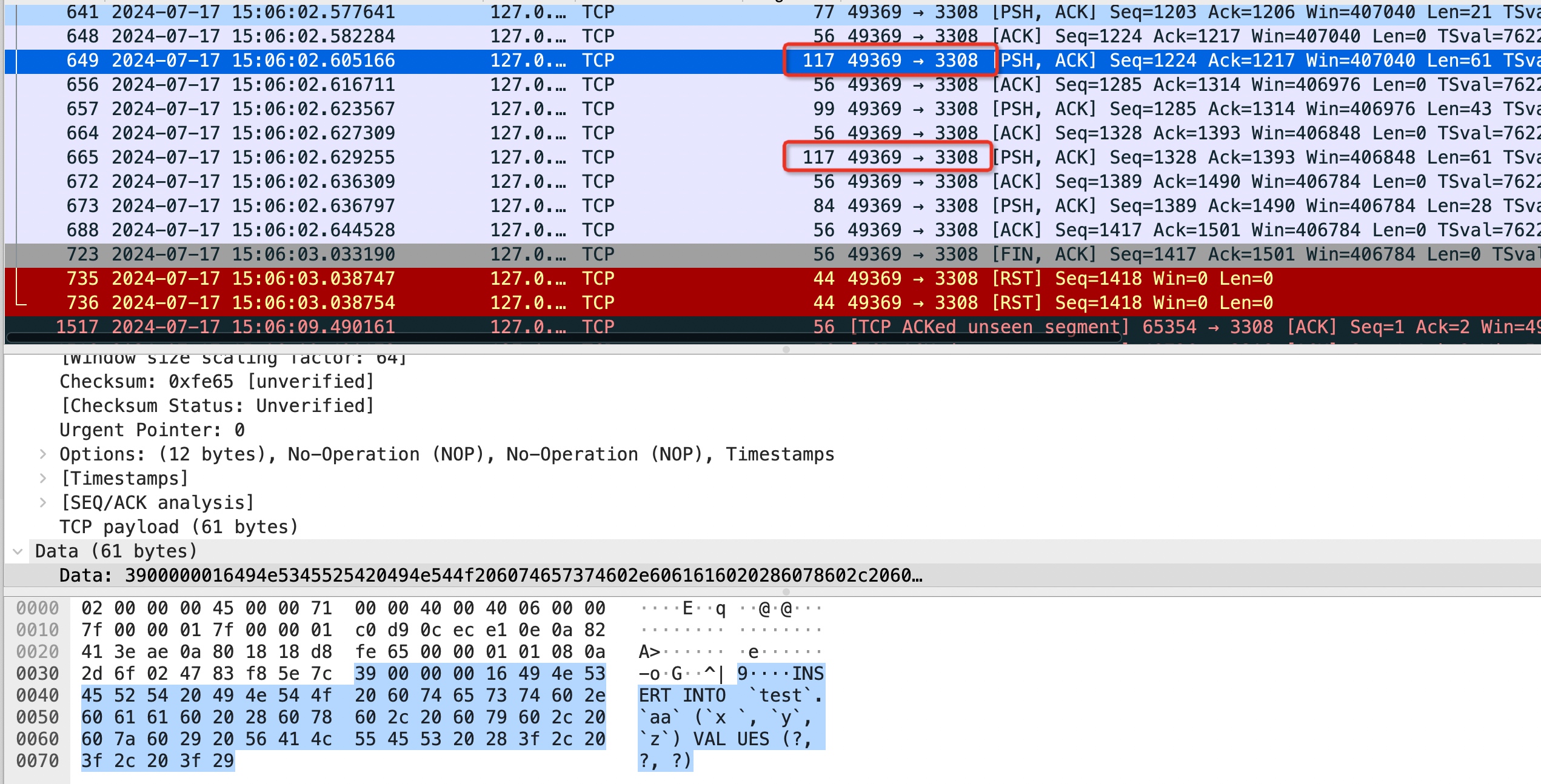
第一次预编译很好理解,而第二次预编译的具体的调用链路如下:
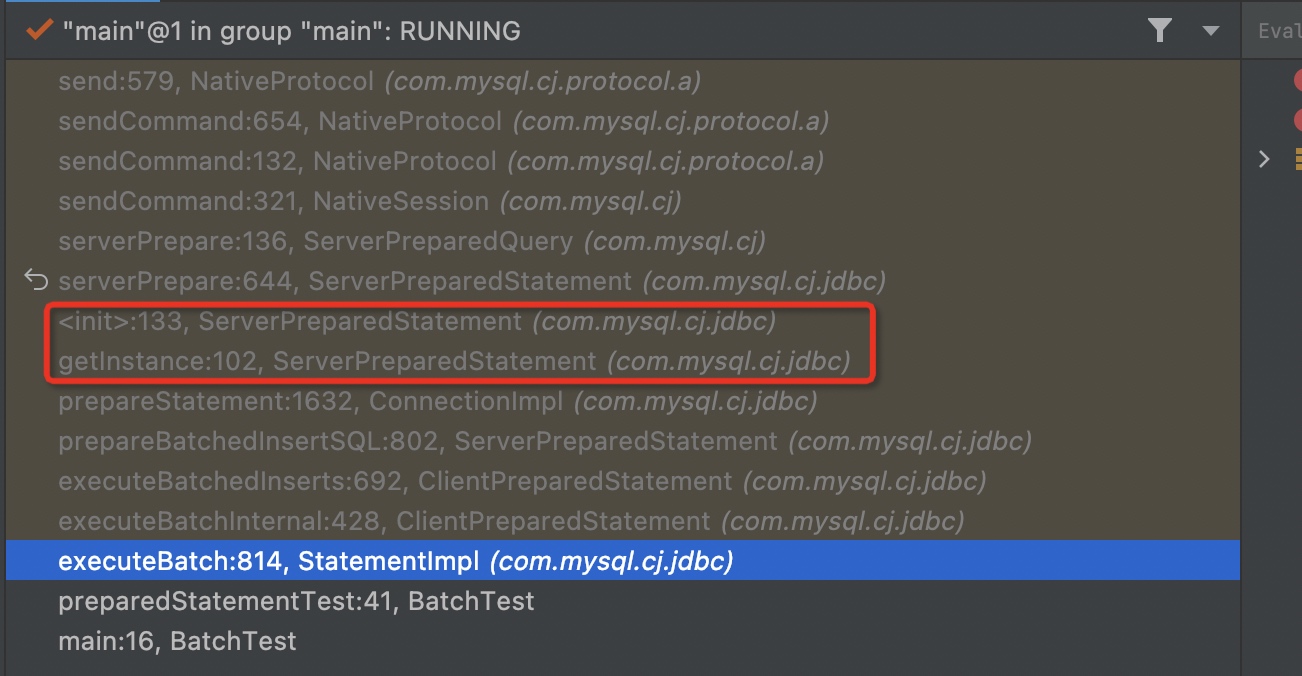
可以看到,在
executeBatch的时候又创建了一个ServerPreparedStatement,而它的构造函数里就会向MySQL发送Prepare命令,预编译这条拼接后的SQL。返回值问题
注意:对于批量SQL的返回值指的是影响行数
普通模式下的返回值
multi-value insert的返回值
返回插入的行数
用;拼接的批量插入
返回第一条语句的插入行数。
虽然抓包每一条语句都会返回执行结果和影响行数。
batchUpdate的返回值
返回更新的记录行数
用;拼接的multi-queries更新
返回第一条语句的更新行数(命中行数,而不是实际产生更新的行数)。
虽然抓包每一条语句都会返回执行结果和影响行数。
batch模式下的返回值
batchInsert的返回值
这里针对是否rewrite是两种不同的返回值:
- 在不rewrite的情况下,
executeBatch返回值int[]里针对每一条语句,返回的就是实际插入的记录数量。
- 而在rewrite的情况下,由于无法拿到每条语句的实际插入数量,索性把每一条语句的更新行数设置成一个固定值(-2),表示成功但是影响行数未知。
而是否rewrite则取决于使用的
Statement 类型以及rewriteBatchedStatements 配置。下面这坨就是使用
PreparedStatement 并且开启了rewriteBatchedStatements 的处理代码。写得真是灾难现场啊,简简单单一段逻辑给写得这么晦涩难懂。想要实现的逻辑是:对batch里的insert语句做rewrite时,按照maxAllowedPacket做拆分,单次请求的大小不能超过maxAllowedPacket。batchUpdate的返回值
批量更新并不会合并语句,所以返回值不会像insert一样出现未知的情况。但是
PreparedStatement批量更新里考虑了一种特殊场景,就是add到batch里的语句本身就是用; 拼接的多条更新语句。这样在rewrite成multi-queries之后其实看起来就像单条语句rewrite之后的一样,它最终返回的int[]的数量其实是所有拆分后单条更新语句的影响行数。以上情况仅针对批量update在rewrite场景下。非rewrite场景,那么返回的
int[] 数量不会考虑拆分逻辑,并且只会取; 分割的第一条语句的影响行数。而普通的
Statement 在batch模式下如果添加了用; 拼接的多条更新语句,则在执行时会报错:事务问题
批量执行和事务完全是八竿子打不着的两个概念。当然有一种特殊情况,就是batch模式下insert语句被rewrite成一条
multi-value的insert语句,这样的语句是会保证一起成功/一起失败的。但是不同的批次之间也没有事务保证。而通过
;连接的语句,到mysql之后都是分开执行的,都不存在事务。但是执行是有顺序的,比如第一条语句执行失败了,后续的语句就不会再执行了。批量插入如何拿到自增主键
我们从MySQL拿插入后的自增主键值的方式有两种:
- 通过JDBC规范提供的
Statement.getGeneratedKeys()方法
- 通过在同一个Session里执行SQL
SELECT LAST_INSERT_ID()
对于MySQL来说,我们一般都使用第一种,因为能减少一次数据库交互。并且,在批量插入的场景下,第一种方式支持得更好。
下面就以第一种方式为例,看看不同的批量插入场景:
- 通过
;连接的多个单条插入的语句
- multi-value insert语句
- 通过addBatch串联起来的批量插入语句
通过;连接的多个单条插入的语句
这种批量插入执行过程抓包如下:
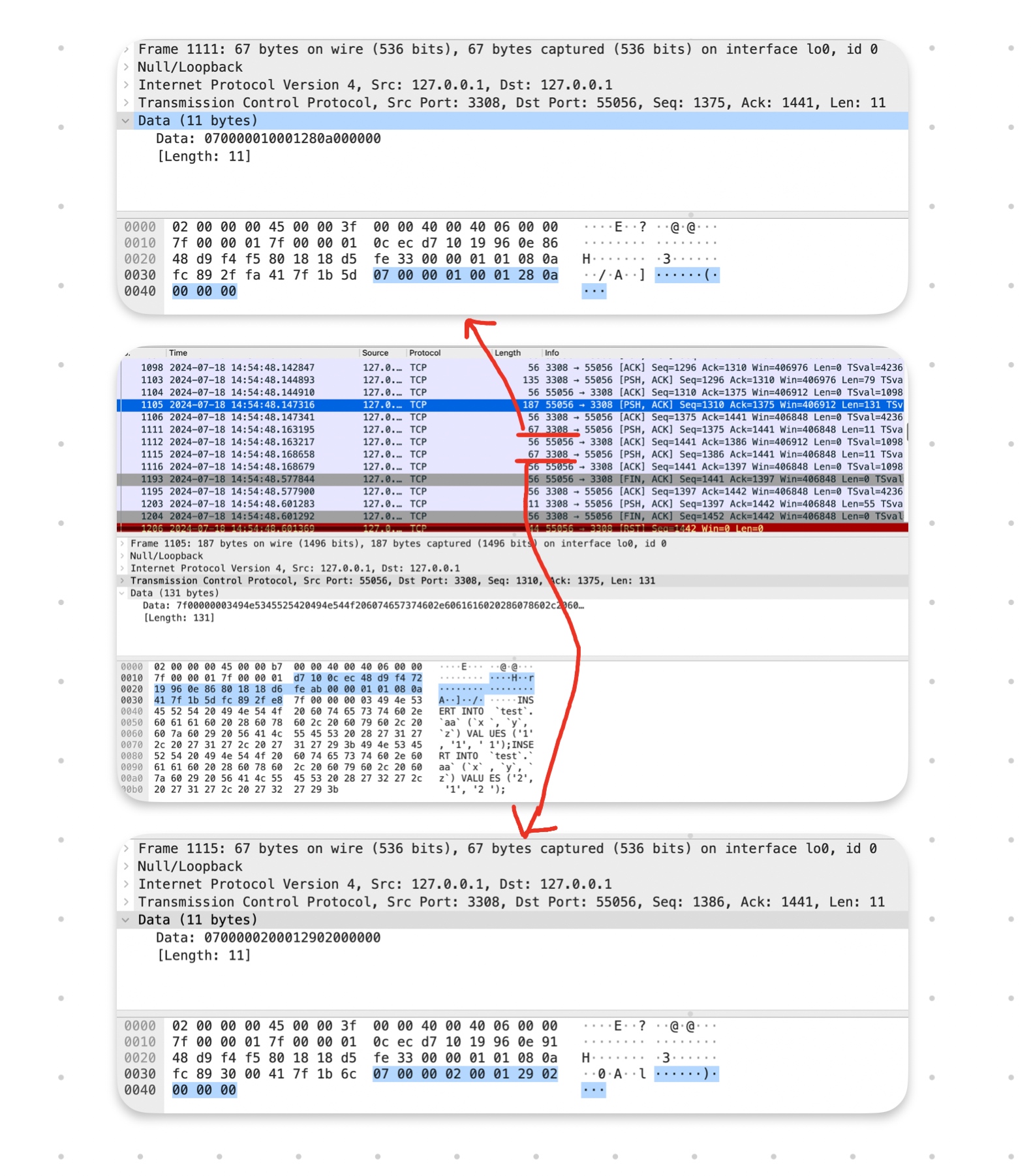
可以看到它一次返回了每一条插入语句的执行结果和对应的自增主键。但是遗憾的是,在取值的时候,只取到了第一个:
multi-value insert语句
没有任何意外,可以按顺序拿到所有的自增主键
通过addBatch串联起来的批量插入语句
没有任何意外,可以按顺序拿到所有的自增主键,但是存在一个特殊场景。
batch模式下的一个特殊场景
如果在batch模式下,使用
Statement 并且存在multi-value的insert语句,那么在执行后通过获取自增主键时,可能会丢失。
multi-value的语句只能返回第一条自增主键。而在使用
PreparedStatement 的情况下,不存在此问题。性能隐患
批量语句的主要性能隐患就是可能会产生超大的SQL。
- 一方面可能导致应用的内存占用升高,甚至溢出
- 另一方面可能造成大事务
所以在使用的过程中必须要注意每批次的大小。
参考
- Author:黑微狗
- URL:https://blog.hwgzhu.com/article/mysql-batch-sql
- Copyright:All articles in this blog, except for special statements, adopt BY-NC-SA agreement. Please indicate the source!
Relate Posts