type
status
date
slug
summary
tags
category
icon
password
AI summary
背景
前段时间吉卜力生图还挺🔥,我在小红书蹭蹭热点,帮没有plus会员的朋友免费出图。没想到一下子火了,出图量有点大,人肉搞是不现实了,于是准备通过automa这个chrome插件来自动化。之前有过影刀的使用经验,讲道理也比较容易上手(对了,automa去年也被影刀收购了🤦🏻♀️)
设计
自动化程序我设计了两个大模块:采集和出图
- 采集是通过采集小红书的评论数据来生成待出图任务
- 出图是通过轮训待出图任务,扔到gpt-4o里生成图片并获取结果
众所周知现在gpt-4o都还没有官方api,所以出图我们也是通过automa来模拟操作实现的
问题
具体的步骤我就不详细描述了,只记录过程中碰到的一些问题
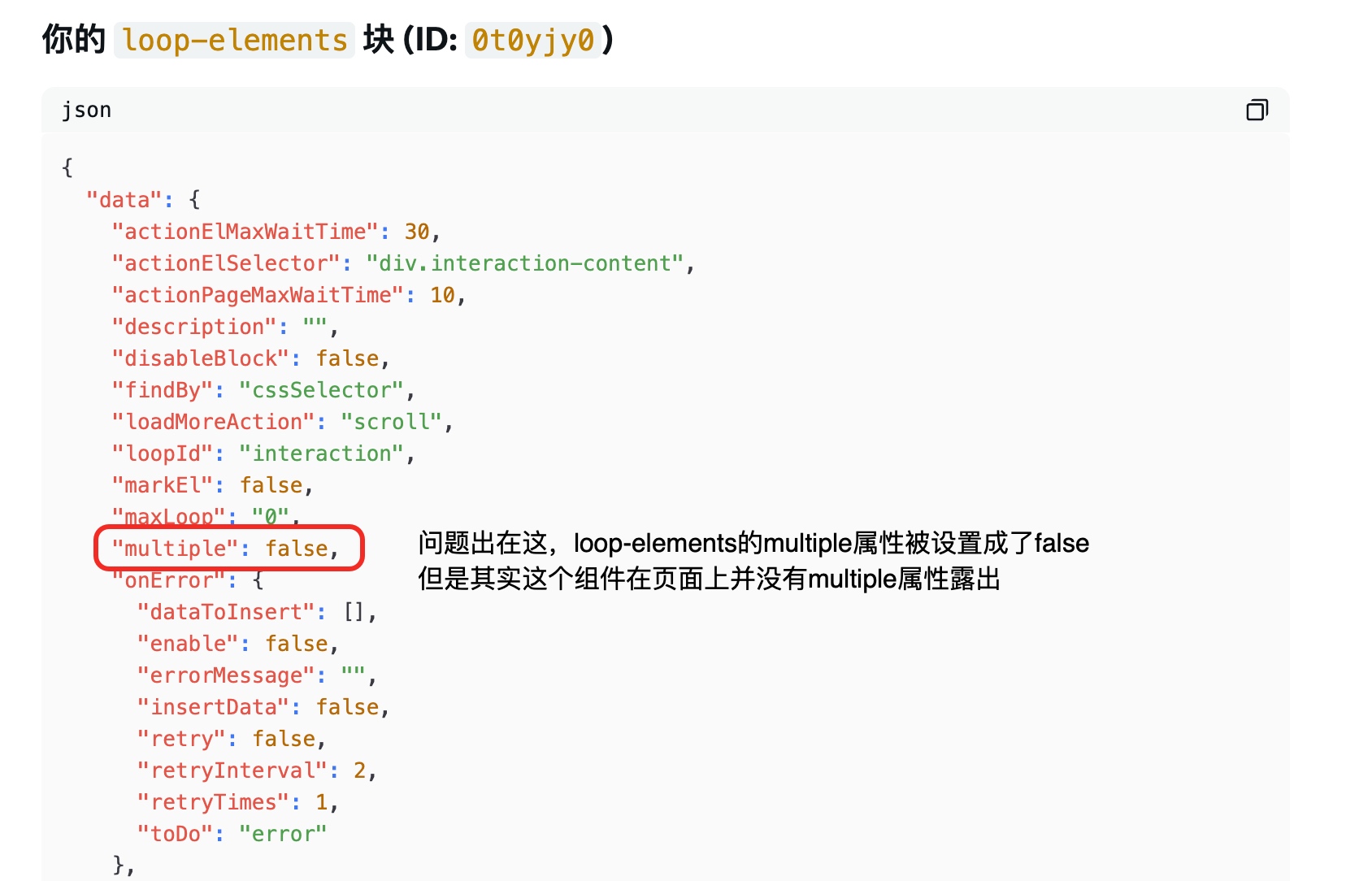
loop elements报错TypeError: s.forEach is not a function
这个问题定位了很久,最终还是把任务json丢给grok才找到问题的原因。loop elements在页面上根本没有是否multiple的配置,默认应该是都true,但是不知道在什么情况下,被变成了false。所以最终获取到的s并不是一个元素列表,而是一个元素,导致报错。感觉应该是我从A电脑上传到云端,然后B电脑从云端下载编辑又上传,最后再在A电脑上下载脚本后使用这个链路有关。还得看看两遍是不是一个版本。github上也有人提过同样的问题,但是也没有人解答:TypeError: s.forEach is not a function
操作google sheet报错internal server error
本来想做得简单一些,直接纯用automa里的组件完成。关于待出图任务的存储,准备存到google sheet里。遗憾的是,google sheet读取没问题,但是写入直接报错。一开始是怀疑自己的打开方式不对,试了很多次,最终在github上看到了类似的issue感觉应该是automa的bug。于是放弃了google sheet。并且使用google sheet会有不少的局限性,比如我采集侧其实需要做去重处理,用google sheet感觉根本没法做。
最后无奈采用自建服务,通过http接口来把评论数据落到mysql中。
http请求body里有换行符
Automa官方文档写了这种body里某个字段值包含换行符的配置方法:需要去掉包裹的双引号,并在变量名前增加感叹号。相关文档

但是对于loopData貌似不生效,换成variables就起效果了。
最佳实践
循环方式
- Repeat Task Block:适合明确次数的循环
- While Loop Block:适合明确条件的循环
- Loop Data Block:适合有列表数据的循环
- Loop Elements Block:适合有列表元素的循环
这几个循环的使用场景很容易理解,但是在配置上需要注意一下:
- Repeat Task Block:需要通过连线指定repeat from的位置
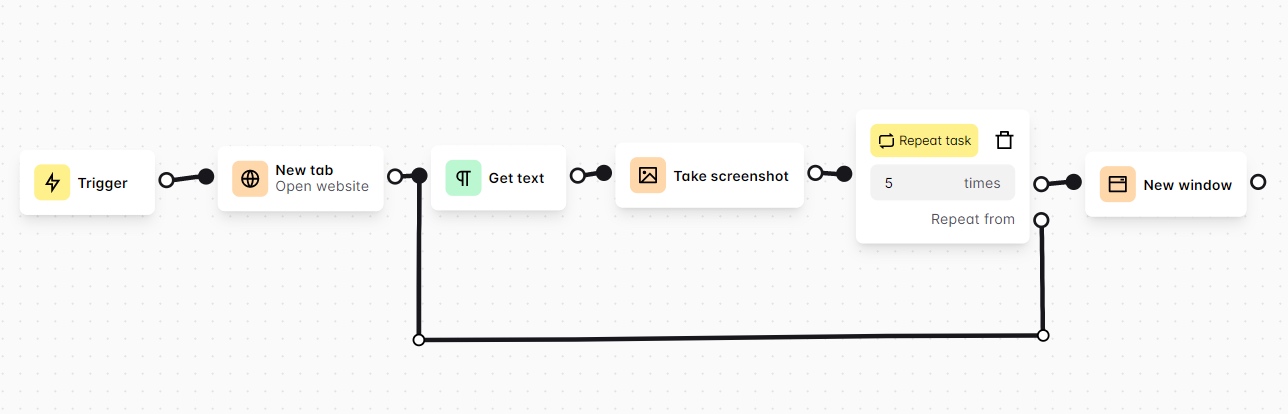
- While Loop Block:需要通过连线跳回while loop进行条件判断

- Loop Data Block/Loop Elements Block:需要通过添加Loop Breakpoint Block来标记循环区间
table/storage
这个是Automa自己的数据存储,如果仅仅只是简单采集的话可以使用,或者是调试阶段观察数据。
数据抓取
我主要用的是
Get Text和Attribute value这两个节点来抓取页面数据。抓取之后可以保存到table里也可以保存到variables里。Get Text
Get Text对于定位到的元素,可以抓取的内容形式有以下三种:- 仅包含可视文本:默认行为
- Include HTML tags:包含HTML标签
- Use textContent:包含所有的文本,无论是否visible,包括
<script>和<style>元素
Attribute value
这个节点不仅可以获取,还可以设置Attribute value,不过我暂时没有用到
怎么写selector
关于selector,可以先尝试使用Automa提供的
element selector工具定位,不过大概率可能不符合我们的诉求,需要自己微调一下,然后在console尝试输出,并用verify工具来验证。不断的调整,慢慢逼近我们想要获取的元素。常用变量
整个
workflow可以使用的变量在Execution log里就有体现:我常用的就是
loopData和variables这两个,loopData需要在循环体里使用,而variables则是自己通过Get Text、Attribute value等节点抓取到的内容。如果是在循环里写入variables,需要注意在新循环开始的时候把里面的变量手动清空,不然如果第二轮循环某个字段没获取到值,可能会错误的使用到前一轮的值。
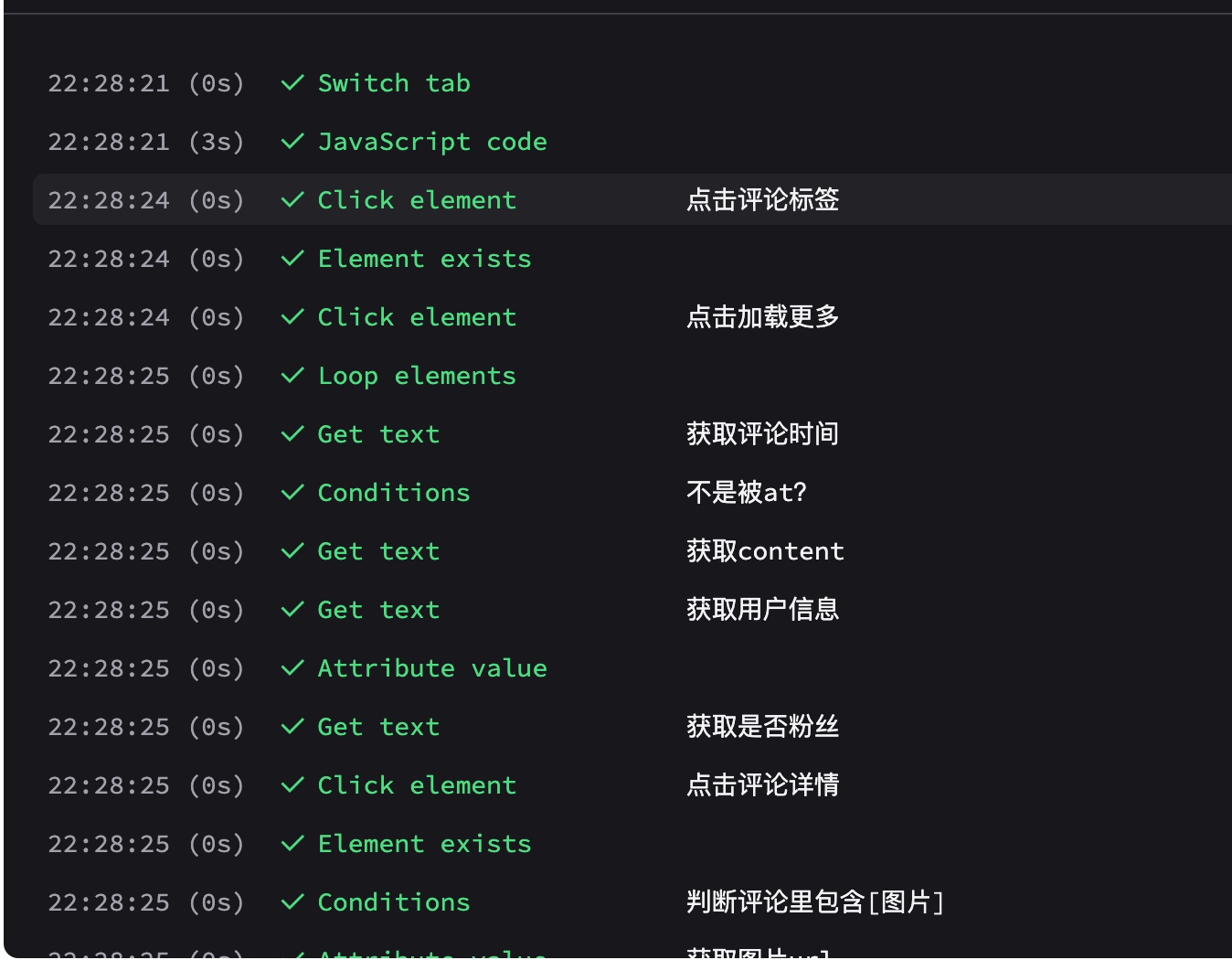
给每个节点命名
如果你愿意给每个节点命名,那么在看日志的时候会节省你很多时间:
关于JavaScript code
Execution Context
这个组件主要就是对于Execution Context的选择:如果涉及到页面上的DOM操作(比如读取或者修改),那么选Active tab,否则就选Background
内置函数
暂时就用到下面三个内置函数:
- automaNextBlock(data, insert?):用来继续向下流转,js代码块最后一行默认就是这个,我的使用场景里暂时没用到里面的参数
- automaSetVariable(name, value):用来设置变量,整个workflow都可用
- automaRefData(keyword, path):用来提取变量
修改页面元素
看了下chatgpt的聊天窗口的输入元素并不是
<input>,而是一个<p>,所以没办法使用表单元素来填充。只能用js代码来替换页面元素。今天看文档发现有一个一个Create element节点里有一个replace target element选项应该也能实现这个功能。
配置定时执行
这块其实本来没什么好说的,无非就是配置一个cron表达式以及其他几种定时策略。比较坑的是配置之后发现无法修改,原来是还要通过【+ Schedule Workflow】才能找到其删除入口
日志保留策略
Automa默认每次运行的日志只保留前1000条,后面应该只记录ERROR日志,可以通过设置里调整的大一些
容错处理
由于这种直接通过页面来自动化的操作及其依赖页面元素,并且会有很多难以预料的场景(比如很多UGC的内容、很多平台不同的类别等等),所以需要大量的容错处理,不然自动化程序很容易报错而终止运行。
判断元素是否存在
Automa提供了一个用来判断元素是否存在的节点——
Element exist block,这样可以根据某个元素是否存在走不同的分支流程,不至于报错。我的采集流程里可能会存在一个【加载更多】的按钮,如果存在,那就要把它点开。设置超时时间
- Wait for selector:获取页面元素的节点都可以配置一个等待时间,如果目标selector对应的元素暂时不存在的话,会等待对应的超时时间。
- Wait until the tab is loaded:创建新的tab页时等待其加载完成再进行后续的操作
设置节点的异常处理
我们可以给节点配置异常处理策略:
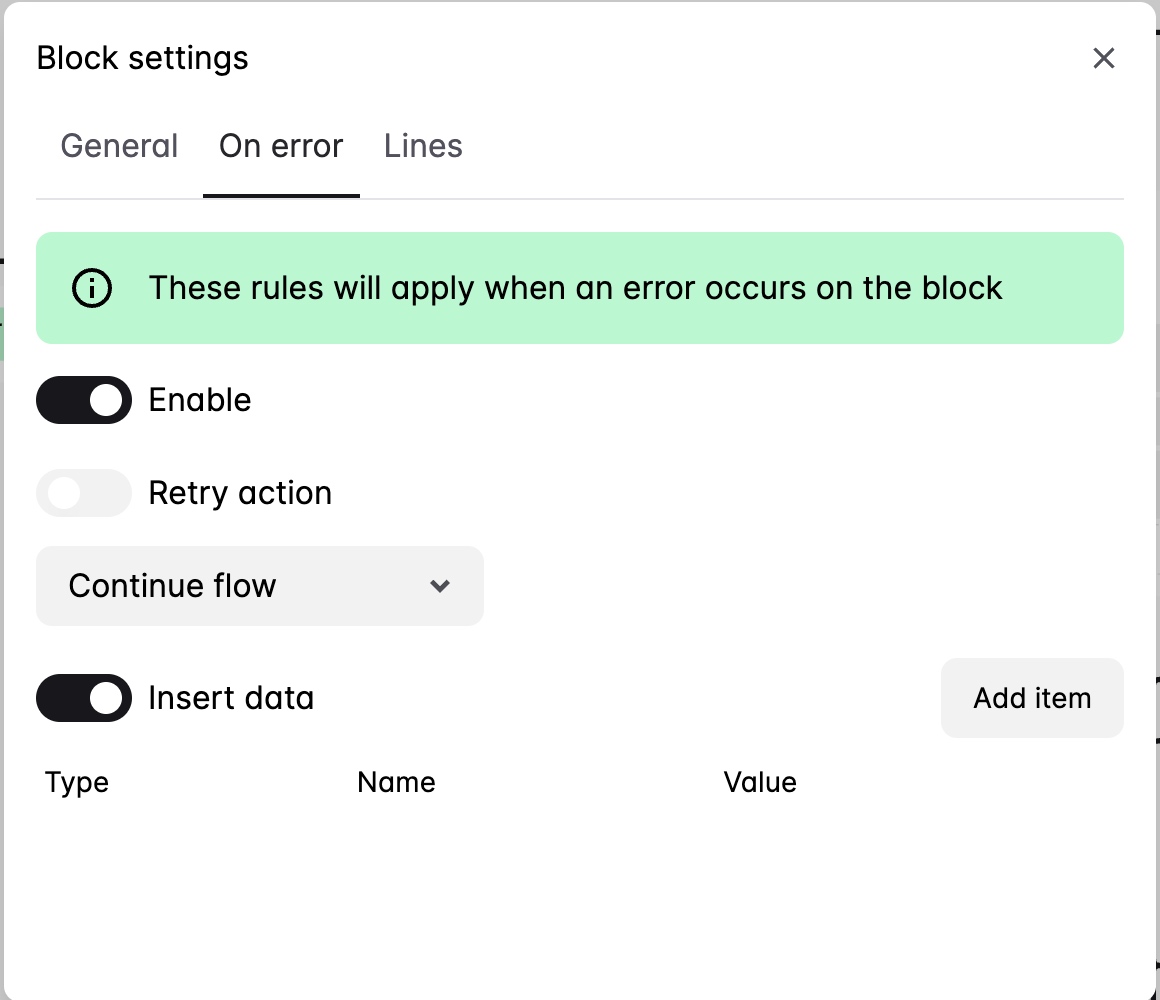
- Throw error(默认策略):直接报错
- Continue flow:忽略异常,继续流程。比如获取某个元素没获取到的时候,可能属于正常情况,只让那个字段置空就行了,不要影响整个流程。
- Execute fallback:执行fallback流程
并且看起来还可以把异常信息记录到table里(这个功能我没用过)
设计不同的重试策略
gpt-4o画图的异常场景还挺多的,比如:
- 接口稳定性问题:不稳定、生成图失败、有时候甚至网页都打不开
- 图片本身问题:可能违反了内容政策等等
- 限流:调用频次或者数量在某个时间段内达到了限制
- 前端问题:可能图片已经创建完了,但是前端页面一直没感知,刷新一下就可以了
所以我简单做了一个升级的重试策略:根据重试次数走不同的分支
- 每重试10次(50秒左右),就刷新一下页面获取最新的结果
- 每重试120次(10分钟左右),就直接更新任务为失败,进行下一张图片的生成
其他
需要注意采集频率,增加Delay节点,以免被平台识别出异常行为,被封号等
后记
之前对于Automa只有了解,但是完全没有入门,通过这次的实践,感觉终于掌握了Automa的基本使用。但是不得不说,个人觉得入门还是有一定的难度。
gpt-4o官方一直没有提供api,网上流传的api是不是通过这种方式来提供的?我觉得按照我这种方式也是完全可以提供API的。
还可以把Automa和n8n结合起来,n8n有更丰富的生态和插件,这样我们就不需要自建服务端,完全通过低代码来构建。
- Author:黑微狗
- URL:https://blog.hwgzhu.com/article/automa-use-case-recrod
- Copyright:All articles in this blog, except for special statements, adopt BY-NC-SA agreement. Please indicate the source!