type
status
date
slug
summary
tags
category
icon
password
AI summary
COPY
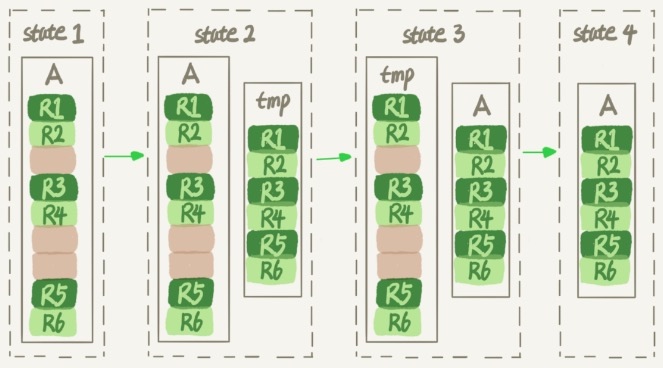
MySQL 5.5之前的版本,对于DDL只支持以COPY表的方式来进行。COPY是一种性能较低的算法,是由Server层通过创建一个临时表的方式来进行数据复制,大致流程如下:
- 创建临时表(也叫影子表)
- 对临时表应用DDL
- 对原表加写锁,禁止DML
- 把原表记录逐行从复制到临时表中
- 对原表加读锁,禁止查询
- 删除原表,把临时表名更新成原表名
下图展示了过程中的数据变化:
如果使用的是这些版本的MySQL,对于大表结构变更用的比较多的 DDL 操作工具是
pt-online-schema-change 或是 gh-ost,当然现在用的也比较多。INPLACE
而从MySQL 5.5开始,推出了另一种算法:INPLACE。这种算法和COPY不同的是:INPLACE完全是在InnoDB存储引擎层自行处理,不需要Server介入,所以得名“原地更新”。
INPLACE算法最初的应用就是在
Fast Index Creation上。FIC改变了二级索引的添加和删除流程,不再需要使用COPY的方式,把整个表结构和数据都复制一遍,只需要通过读取聚簇索引来构建新的二级索引即可,不仅减少了Redo log、Undo log等的写入,也减少了聚簇索引以及其他二级索引的复制。FIC的大致流程如下:- 对原表加写锁,禁止DML
- 读取聚簇索引
- 使用二级索引字段排序,构建新的二级索引树
- 把二级索引数合并到ibd文件
虽然FIC对整体的性能做了不少的提升,但是在执行期间还是无法进行DML操作。所以MySQL 5.6在FIC(INPLACE)的基础上,正式推出了Online DDL的概念。
什么是Online DDL呢?区分是否Online的唯一标准就是在DDL执行期间,能不能对原表并发执行DML。当时的Online DDL基本等同于INPLACE算法,但是随着MySQL的发展,在8.0.12版本还引入了INSTANT算法,这是一种更高效的Online DDL算法(当然它也属于inplace更新)。所以下面我们会用具体的算法名称来介绍具体的算法流程。当时的INPLACE算法能做到支持并发DML的主要是通过区分了DDL的类型,比如:
- 区分了DDL是否
Only Modifies Metadata - 比如删除二级索引,Only Modifies Metadata
- 重命名索引,Only Modifies Metadata
- 区分了DDL是否需要
Rebuilds Table - 比如删除字段,需要 rebuilds table
- 比如修改字段类型,需要 rebuilds table
对于第一种类型,只修改元数据,本身执行速度就非常快,所以几乎也不存在影响读写请求。而对于第二种类型里不需要
Rebuilds Table的DDL,多数其实都属于Only Modifies Metadata,有一种比较特殊且常见,就是添加二级索引,这个我们一会再说。下面先看看成本最高的,需要Rebuilds Table的大致流程,整体分成了三个阶段:- Initialization
- 加X锁,防止其他DDL并发执行
- 根据DDL语句上指定的ALGORITHM和LOCK来计算Execution阶段需要升级到的锁粒度
- 更新数据字典的内存对象
- 如果需要Rebuilds Table,那么去创建临时表文件
- 如果需要Rebuilds Table或者是创建二级索引,那么去创建row_log文件
- Execution
- 根据Initialization的评估,来决定锁是否降级以及降级到哪种粒度
- 如果需要Rebuilds Table,那么去读取聚簇索引,构建新的聚簇索引树和二级索引树,并合并写入临时表文件
- 如果是创建二级索引,那么去读取聚簇索引,构建新的二级索引树,并合并写入原表文件
- 如果支持并发读写,那么对于并发执行的DML,记录到row_log中
- 应用row_log里的变更记录到新表中(非最后一个block)
- Commit Table Definition
- 升级至X锁,禁止读写
- 应用row_log里最后一个block的变更记录到新表中
- 更新 InnoDB 的数据字典
- 提交 DDL 事务
- 清理操作 Clean Up
可以看到过程中也需要禁止原表读写,不过时间相对来说都比较短,并且不会随着数据量的增加而明显变长。而对于其中最耗时的部分已经Online了。
看到这里你可能会问,INPLACE算法下的Rebuilds Table也是要复制表,那和之前的COPY算法有什么区别呢?他们的主要区别是:COPY算法是Server层通过创建了一张临时表,然后逐行复制,其中会写redo log、undo log等等。而Rebuilds Table是直接通过读取ibd文件生成新的索引树,对于磁盘和cpu的消耗会降低不少。下图展示了过程中的数据变化:
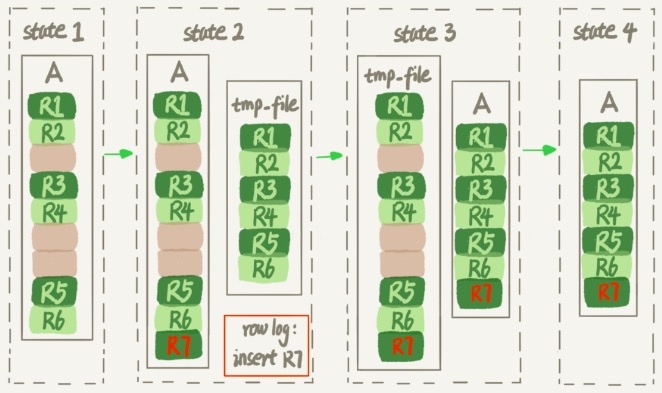
之前我理解的应用row_log和执行DDL变更是不同的线程在执行的,但是看了网上的一些源码分析,感觉上应该是单线程执行的。在通过原表聚簇索引构建完新的索引之后,就会进入到应用row_log的流程中,并且row_log是按照一个个block组织的(block的大小由innodb_sort_buffer_size确定,默认值为1M)。每切换到一个block,都会短暂的加一下X锁,如果该block不是最后一个block,则先解锁,再应用。直到切换到最后一个block,此时会一直加X锁直到全部row_log应用完,至此新老索引达到一个一致性的状态。
INSTANT
8.0.12版本
可以看到,INPLACE的性能问题主要还是存在于Rebuilds Table的场景。是否Rebuilds Table主要取决于数据格式有没有更改,比如新增字段,删除字段,对数据格式都有改动,所以都只需要Rebuilds Table,而新增字段又是一个业务迭代过程中非常频繁的一个诉求。所以在MySQL 8.0.12版本,引入了一种新的算法——INSTANT。这种算法可以快速的添加新列。它是如何做到的呢?下面这张图可以给你一个直观的感受:
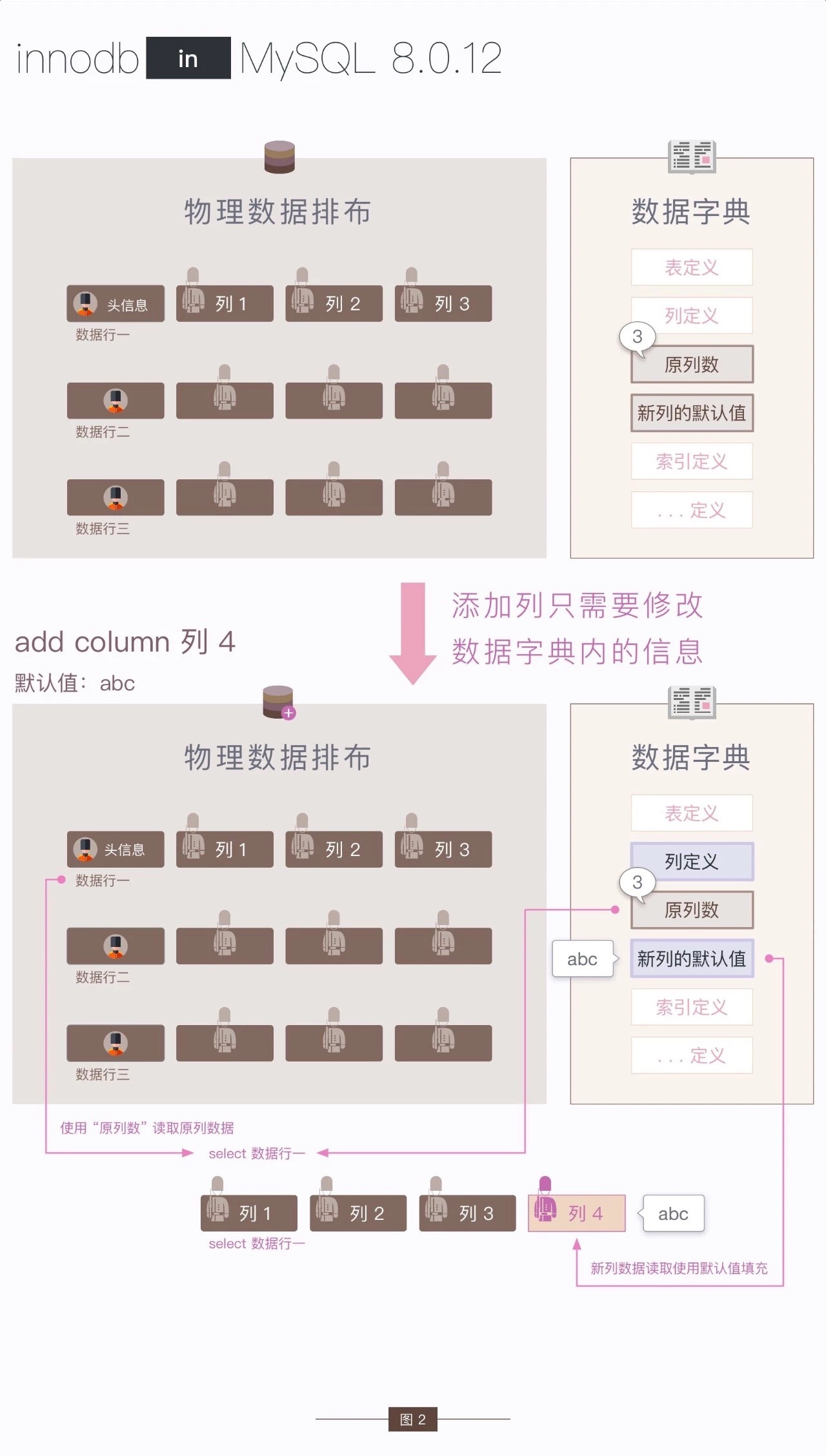
简单来说就是对于新增字段,不再去重建整张表,而是通过
- 在表元数据里增加instant add column之前的原列数来标识instant列
- 在列元数据里增加了列是否有默认值以及对应默认值来标识instant列
- 在row_format里增加行记录的instant标识,以及行记录里的字段数量
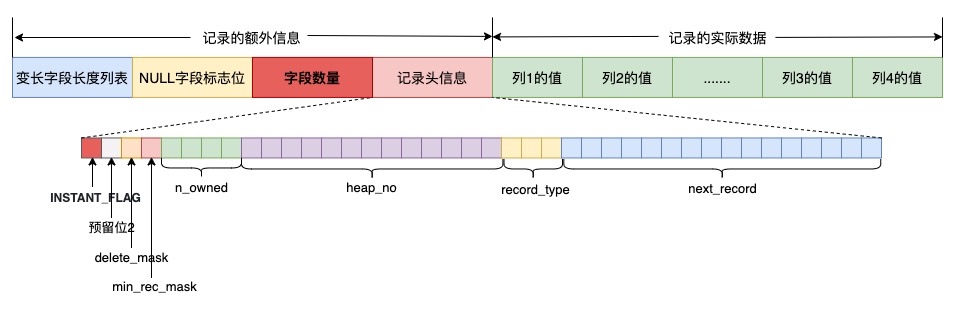
然后在读取数据的时候结合上面两部分信息做一个简单的计算:
首先判断行记录里的instant标识
- 如果为0,代表是instant加列前的数据行,那么需要追加新增的那几列,且都为默认值
- 如果为1,代表instant加列后产生的数据行,那么还需要结合数据行里的字段数量和当前表字段数量判断
- 如果两者相等,那么直接返回行数据即可
- 如果不相等,那么数量之差就是instant列,按列元数据追加最后几列即可
可以看到,此版本对于元数据的记录比较简单,就是通过一个原列数来识别哪些是instant列(原列数之后的列)。那也不难理解对于instant加列的其中的一个约束:新增字段位置必须添加在表字段最后。
可观测
information_schema.innodb_tables 表里的instant_cols字段代表的是instant add column时的原列数,而不是instant列数。具体哪些列是instant列,可以查看information_schema.innodb_columns 表,has_default=1表示instant列,default_value表示默认值8.0.29版本
而在8.0.29版本,MySQL为了更进一步支持instant删列,不再使用表元数据上的原列数来判断instant列了,而是通过在列元数据上增加版本号以及在数据行里增加版本号来计算行数据。这顺带也让instant加列支持了任意位置。先看下行格式的变化,使用到了另一个预留位来标识这种类型的数据。然后增加了一个字节来存储version信息
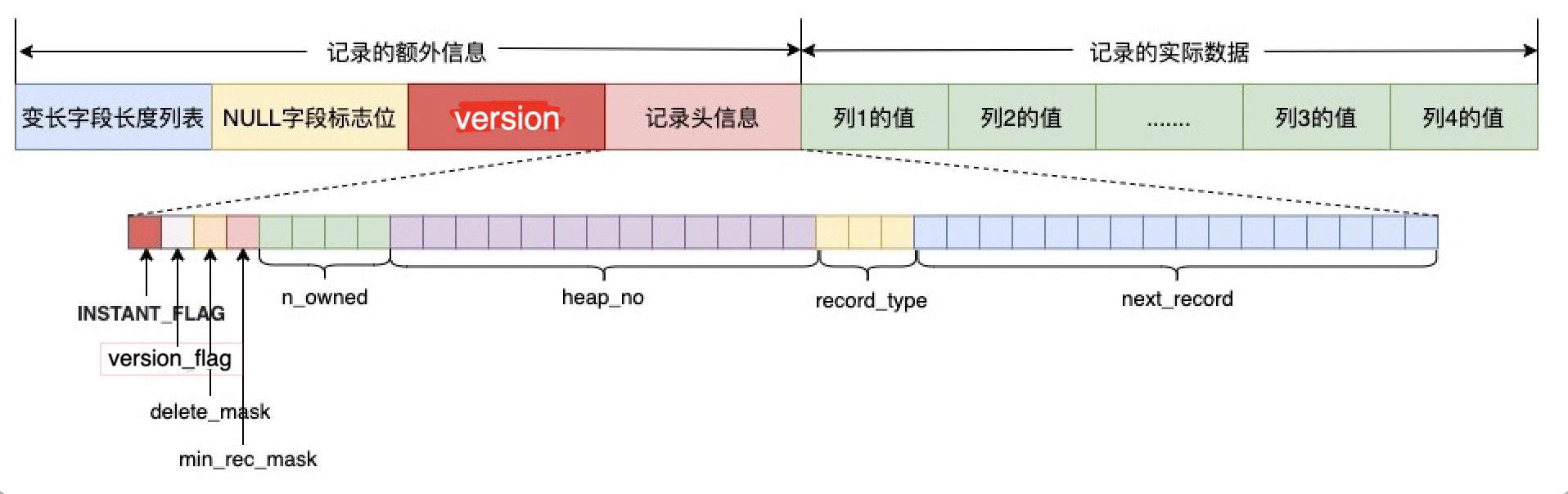
下面再通过一个具体的实例来展示列元数据的变化:
可以看到列c、c2的se_private_data里都记录了添加的版本,b字段被删掉了,也记录了对应的版本。而每一行数据里也记录了这行数据更新时的版本。所以读取一行数据的流程,需要判断行数据上的版本号和表最新的版本号,如果两者相等,则可以直接返回。如果不相等,则需要构建出该版本和最新版本之间的差异数据(少的要补,多的要删)
版本限制
一张表的row version当前的上限是64,如果版本号已经达到64,那么后续就没法走instant加列或者删列了,只能退化成inplace算法。在达到限制后,强制执行instant算法则会报错:
可以通过下面的SQL来观察表的row version
另外需要注意的是,如果说想要instant drop column,该列上不能有索引。如果有索引的话需要先调整相关索引之后再instant drop column。
参考
- INSTANT算法相关
- Author:黑微狗
- URL:https://blog.hwgzhu.com/article/online-ddl-evolution
- Copyright:All articles in this blog, except for special statements, adopt BY-NC-SA agreement. Please indicate the source!