type
status
date
slug
summary
tags
category
icon
password
AI summary
MySQL 主从复制原理
我们先看看MySQL主从复制的工作原理:
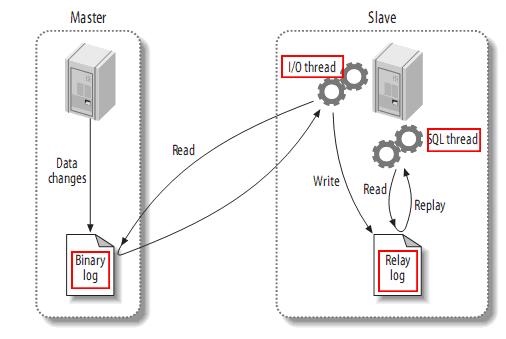
主从复制的整体流程如下:
- 主库在事务内写入binlog
- 主库通过dump线程和io线程之间建立的连接,把binlog event传输给从库
- 从库IO线程读取到主库传输的binlog event,写入本地的relay log
- 从库的SQL线程读取relay log,回放对应事务操作
MySQL 5.6并行复制架构
MySQL早期版本(5.6之前)的主从复制都是串行的,这里关于串行和并行的描述指的都是从库的SQL线程。不难想象,使用串行复制必然会带来主从延迟的问题。因为主库上的事务都是并行操作的,而到从库只有一条SQL线程串行执行。
MySQL 5.6推出了并行复制的第一个版本,虽然只实现了库级别(schema)的并行复制,但是它奠定了并行复制的线程模型。原本的SQL线程变成了1个coordinator线程 + 1个worker线程池。
coordinator线程主要负责两部分的内容:
- 判断事务是否可以并行回放,若判断可以并行回放,那么选择worker线程执行事务的二进制日志。
- 若判断不可以并行执行,如该操作是DDL,亦或者是事务跨schema操作,则等待所有的 worker 线程执行完成之后,由coordinator线程执行当前的日志。
这里贴一张姜老师整理的架构图:
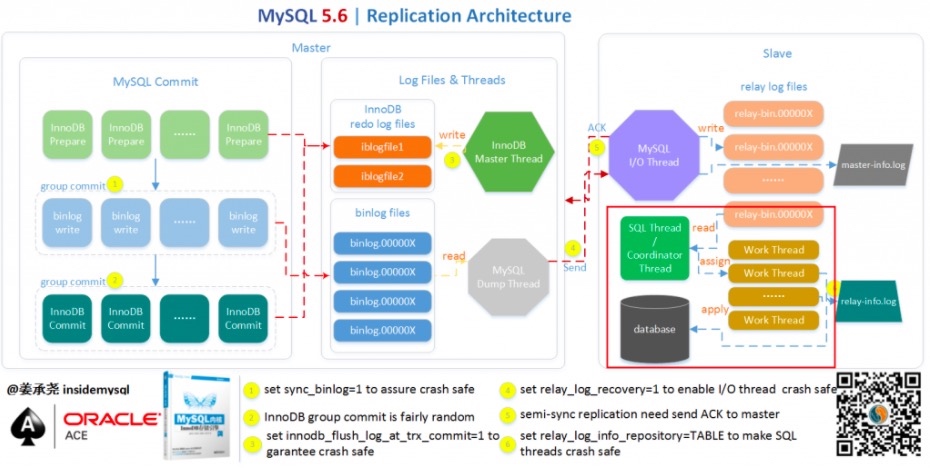
不过这个版本的并行复制存在两个问题:
- 首先是 crash safe 功能不好做,因为可能之后执行的事务由于并行复制的关系先完成执行,那么当发生 crash 的时候,这部分的处理逻辑是比较复杂的。从代码上看,5.6 这里引入了 Low-Water-Mark 标记来解决该问题,从设计上看(WL#5569),其是希望借助于日志的幂等性来解决该问题,不过 5.6 的二进制日志回放还不能实现幂等性。
- 另一个最为关键的问题是这样设计的并行复制效果并不高,如果用户实例仅有一个库,那么就无法实现并行回放,甚至性能会比原来的单线程更差。而单库多表是比多库多表更为常见的一种情形。
MySQL 5.7 并行复制
MySQL 5.6 基于库的并行复制出来后,基本无人问津,在沉寂了一段时间之后,MySQL 5.7 出来了,它的并行复制以一种全新的姿态出现在了 DBA 面前。MySQL 5.7 才可称为真正的并行复制。
从 MySQL 官方来看,其并行复制的原本计划是支持表级的并行复制和行级的并行复制,行级的并行复制通过解析 ROW 格式的二进制日志的方式来完成,WL#4648。但是最终出现给小伙伴的确是在开发计划中称为:MTS(Prepared transactions slave parallel applier),可见:WL#6314。该并行复制的思想最早是由 MariaDB 的 Kristain 提出,并已在 MariaDB 10 中出现。
在讲并行MySQL 5.7的并行复制方案之前,我们要先介绍一下组提交,它和这个方案息息相关。
组提交
MySQL 5.6 中引入了 Group Commit 技术,这是为了解决事务提交的时候需要fsync导致并发性不够的问题。简单来说,就是由于事务提交时必须保证 Binlog 落盘,所以需要调用 fsync,这是一个代价比较高的操作,事务并发提交的情况下,每个事务各自获取日志锁并进行 fsync 会导致事务实际上以串行的方式写入 Binlog 文件,这样就大大降低了事务提交的并发程度。当然不止是Binlog写入磁盘存在这个问题,Redo Log同样存在。
MySQL 5.6 中采用的 Group Commit 技术将事务的提交阶段分成了
Flush,Sync,Commit 三个阶段,每个阶段维护一个队列,并且由该队列中第一个线程负责执行该步骤,这样实际上就达到了一次可以将一批事务的 Binlog fsync 到磁盘的目的,这样的一批同时提交的事务称为同一个 Group 的事务。其中Flush阶段 主要完成Prepare Redo Log的刷盘
Sync阶段 主要完成BinLog的刷盘
Commit阶段 主要完成Commit Redo Log的刷盘
Group Commit 虽然是属于并行提交的技术,但是却意外的解决了从机上事务并行回放的一个难题————即如何判断哪些事务可以并行回放。如果一批事务是同时 Commit 的,那么这些事务必然不会互斥的持有锁,也不会有执行上的相互依赖,因此这些事务必然可以并行的回放。
那么如何在binlog里记录这个组信息呢?在 MySQL 5.7 版本中,其设计方式是将组提交的信息存放在 GTID 事件(MySQL 5.6中引入)中。为了标记事务所属的组,MySQL 5.7 版本在产生 Binlog 日志时会有两个特殊的值记录在 Gtid Event 中,
last_committed 和 sequence_number 。这两个值的逻辑这里重点说一下,因为在不少地方看到的描述都有问题,也困扰了我蛮久。last_committed,是在事务进入prepare之前,已经提交的最大的sequence_number(并且由于sequence_number本身就是提交前分配的,理论上应该就是按照提交顺序递增的)
sequence_number,则是在事务提交前,分配的序号,在一个 Binlog 文件内从1开始递增。你解析binlog文件会发现sequence_number的顺序和事务的提交顺序完全一致。
只要换一个文件(flush binary logs),这两个值就都会从 0 开始计数。
MySQL 5.7 基于组提交的并行复制方案,先后经历了两个版本的迭代:
Commit-Parent-Based方案和Lock-Based方案。下面是一组binlog event的last_committed和sequence_number。我们看看在两种不同的方案下从库并行回放的区别:
Commit-Parent-Based 方案

Lock-Based 方案
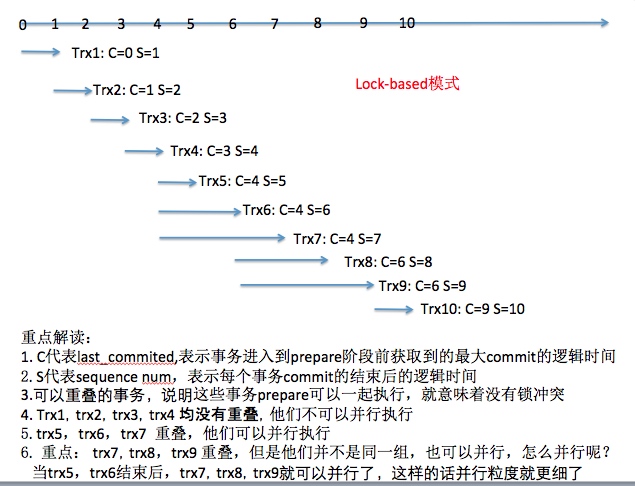
基于组提交的并行复制,回放的并行度很大程度上取决于在主库上执行的并行度。针对主库并行度低的场景,如果想要提升从库的并行回放效率,可调整以下两个参数:
binlog_group_commit_sync_delay
binlog 刷盘(fsync)之前等待的时间。单位微秒,默认为 0,不等待。该值越大,一个组内的事务就越多,相应地,从库的并行度也就越高。但该值越大,客户端的响应时间也会越长。
binlog_group_commit_sync_no_delay_count
在
binlog_group_commit_sync_delay 时间内,允许等待的最大事务数。如果 binlog_group_commit_sync_delay 设置为 0,则此参数无效。当然这两个参数也可以减少主库的磁盘io
MySQL 8.0 基于WRITESET的并行复制
为了进一步提升从库的复制效率,MySQL8.0推出了新的复制模式——
WRITESET。通过参数 binlog_transaction_dependency_tracking 来控制事务依赖模式,有三个取值:COMMIT_ORDERE:使用 5.7 Group commit 的方式决定事务依赖
WRITESET:使用 WriteSet 的方式决定判定事务直接的冲突,发现冲突则依赖冲突事务,否则按照COMMIT_ORDERE方式决定依赖
WRITESET_SESSION:在WRITESET方式的基础上,保证同一个 session 内的事务不可并行
WRITESET这种模式的回放并行度和主库的并行度无关,而是通过另一种思路来解决问题:计算每个事务的修改行,如果两个事务的修改行不冲突,那说明它们可以并行回放。并且这个判断逻辑都在主库消化掉了,最终会体现在
last_committed字段里。也就是说,如果两个事务没有修改到相同的行数据,那么主库会给它们赋相同的last_committed值。这样从库只需要按照之前的逻辑,判断last_committed相同就可以并行回放了。具体的WriteSet的计算逻辑:
WriteSet=hash(index_name | db_name | db_name_length | table_name | table_name_length | value | value_length)
上述公式中的index_name只记录唯一索引,主键也是唯一索引。如果有多个唯一索引,则每条记录会产生对应多个WriteSet值。另外,Value这里会分别计算原始值和带有Collation值的两种WriteSet。所以一条记录可能有多个WriteSet对象。举例来说,下面的表t1,有2个唯一索引:
当用户执行
INSERT INTO test.t1 VALUES (NULL,UUID(),3)时,对产生多个个WriteSet值,分别是:- WriteSet1=hash(PRIMARY|test|4|t1|2|1|8)
- WriteSet2=hash(PRIMARY|test|4|t1|2|1(with collation)|8)
- WriteSet3=hash(idx_b|test|4|t1|2|'2'|1)
- WriteSet4=hash(idx_b|test|4|t1|2|'2'(with collation)|1)
参数
transaction_write_set_extraction用来选择hash函数,推荐设置为XXHASH64,相比MURMUR32有更好的散列性。产生的WriteSet对象会插入到WriteSet哈希表,哈希表的大小由参数binlog_transaction_dependency_history_size设置,默认25000。WriteSet哈希表的类型为std::map<uint64,int64>,保存每条记录的WriteSet值和对应的sequence_number。当事务每次提交时,会计算修改的每个行记录的WriteSet值,然后查找哈希表中是否已经存在有同样的WriteSet。
- 如果所有的WriteSet值都不存在,那么说明本事务和hash表里现存的事务都没有冲突。此时WriteSet值全部插入到哈希表,value值为本事务的sequence_number,并且本次写入binlog的last_committed值使用
m_writeset_history_start
- 如果有WriteSet值冲突,那么取所有冲突值在哈希表里对应的sequence_number的最大值作为本次写入binlog的last_committed值,并且把冲突的value更新为本事务的sequence_number,不存在的WriteSet仍旧插入,value值为本事务的sequence_number
m_writeset_history_start这个变量至关重要,它就是那些不冲突的事务共用的last_committed值,它和哈希表是强关联的,并且它是哈希表初始化前的最后一个sequence_number。而冲突的事务使用的last_committed值其实是和它冲突的上一个事务的sequence_number。当哈希表容量不足时,会清空整个哈希表并且重置
m_writeset_history_start值为当前事务的sequence_number。但是容量不足这一次事务的WriteSet还是会进行冲突判断,并且如果和哈希表有冲突仍然会使用上一次冲突事务的sequence_number,只是这次不会插入自身的WriteSet。对于
WRITESET 模式来说,产生的last_committed值要么是m_writeset_history_start,要么是上一次冲突事务的sequence_number。另外,还有一些场景是无法使用WriteSet的。比如:
- 事务没有写集合。常见的原因是表上没有主键。
- 当前事务的hash函数的设置与全局不一致。
- 表被其它表外键关联。
- 事务写集合的大小超过
binlog_transaction_dependency_history_size。
这些无法使用WriteSet的场景也会和容量不足一样,会把哈希表清空并重置
m_writeset_history_start这三种模式的代码实现上有一点设计模式装饰器模式的感觉,都是在上一个模式上做修饰。比如
COMMIT_ORDERE产生了对应的last_committed值之后,再由WRITESET加工,最后由WRITESET_SESSION加工。参考
- Author:黑微狗
- URL:https://blog.hwgzhu.com/article/mysql-mts
- Copyright:All articles in this blog, except for special statements, adopt BY-NC-SA agreement. Please indicate the source!
Relate Posts