type
status
date
slug
summary
tags
category
icon
password
AI summary
现象
0605傍晚突然出现了下面的异常,这是个比较“新颖”的异常,之前没有见过类似的

分析
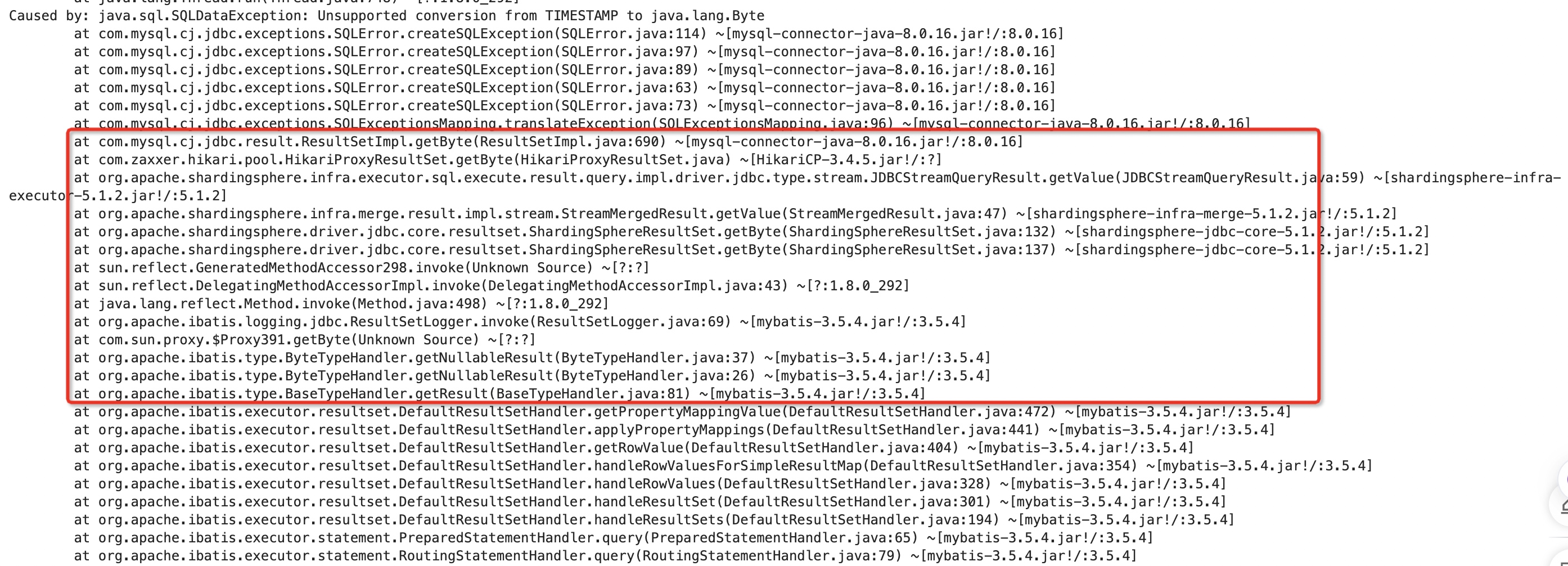
报错信息还是比较明确的:在调用
resultSet.getByte("generate_type")时,发现这一列对应的字段值并不是byte类型的,而是timeStamp类型,所以导致了异常。上图标红的堆栈我们重点关注一下sql有问题?
第一反应是sql语句有问题?难道查询了某个datetime字段并用了generate_type做别名?在查看了sql语句之后,这个可能性就被排除了。sql语句如下:
加字段的影响?
突然想到这张表
checking_cruise好像刚刚添加了一个字段,会不会是加字段的影响。对比了加字段前后的请求,发现报错都是在加字段之后。
并且加的这个字段是有指定位置在remark字段之后的,刚好是添加在了generate_type之前。而generate_type的前1个字段刚好又是datetime字段。这么多巧合,看来问题的原因已经呼之欲出了。

别着急,这里我们先铺垫一些知识点。
知识铺垫
mybatis字段映射
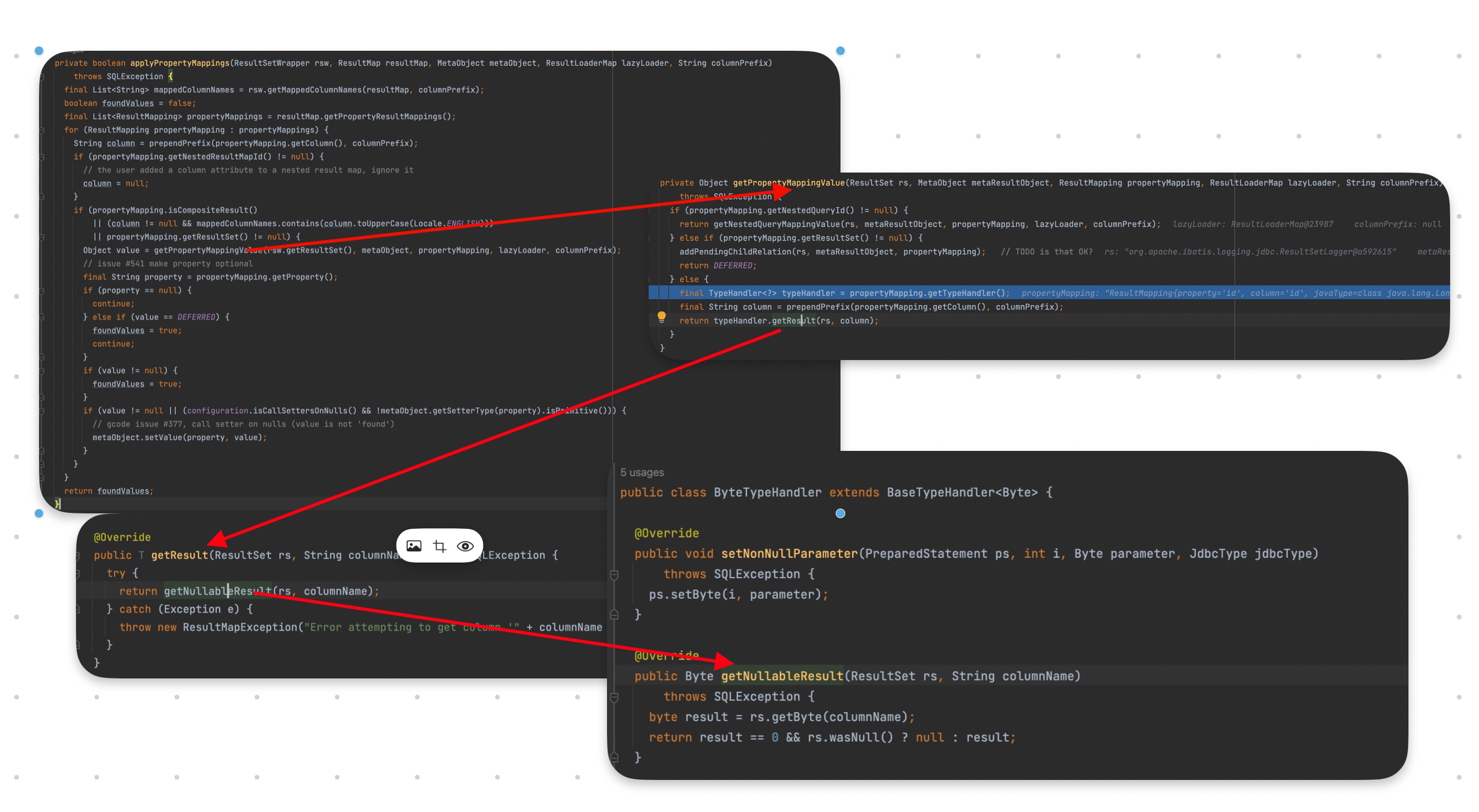
我们知道mybatis是当前比较主流的ORM框架,作为ORM框架,数据库字段和实体类属性的映射就是其最重要的功能之一。上面的代码展示了mybatis是如何根据配置的ResultMap做查询结果集和实体类的字段映射。这里简述一下流程:
- 遍历查询结果集,处理每条记录
- 遍历ResultMap里配置的所有映射关系,处理每个映射关系(上图的for循环就是这个)
- 如果有特殊配置typeHandler,那么优先使用配置的typeHandler来处理字段映射。如果没有,默认根据jdbcType找对应的typeHandler
- 根据配置的column字段值,调用resultSet的getXXX(column)去获取对应值
- 根据配置的property字段值,反射到实体上对应的字段
看起来最终是根据字段名去resultSet里取值的,那为什么还会取错位呢?我们再回顾一下我们的异常堆栈:
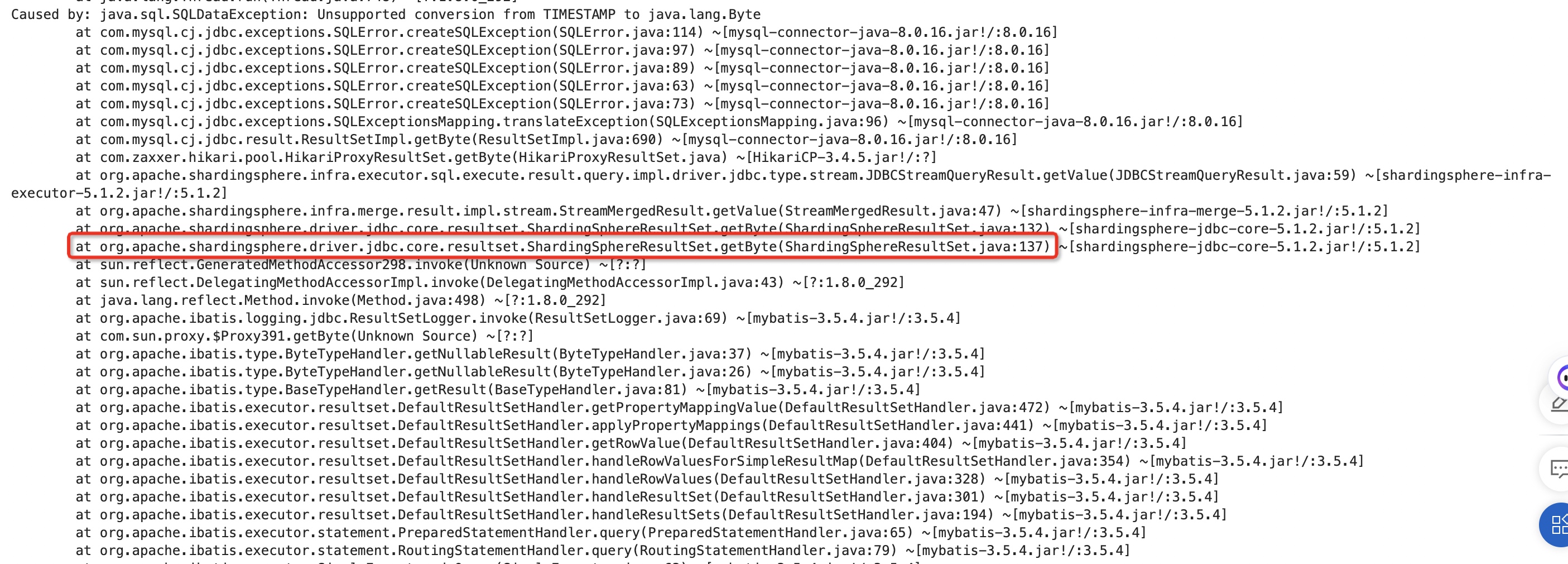
shardingsphere-jdbc
不难看出我们的项目使用到了shardingsphere-jdbc,Mybatis关联的ResultSet的具体实现是
org.apache.shardingsphere.driver.jdbc.core.resultset.ShardingSphereResultSet。我们来看看对应的代码: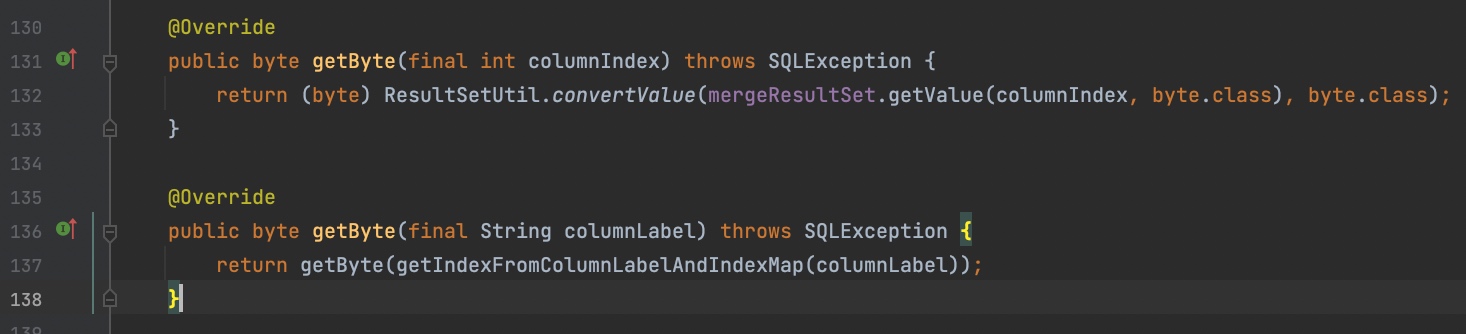
原来根据字段名来取值最终还是被转换成了根据index来取值。那么 columnLabel->columnIndex 这个是怎么转换的呢?

其实,即使是mysql的JDBC驱动,根据字段名取值的底层逻辑也是通过把字段值转换成index先
getResultSet(ShardingSphereResultSet)
可以看到,是通过维护好的一张
columnLableAndIndexMap来做的转换。跟踪了下源代码,columnLableAndIndexMap是在创建ShardingSphereResultSet的时候创建的。并且由于我们的查询语句用了select *,所以创建columnLableAndIndexMap时使用了expandProjections(不过理论上即使你查单个字段,用的应该也是expandProjections)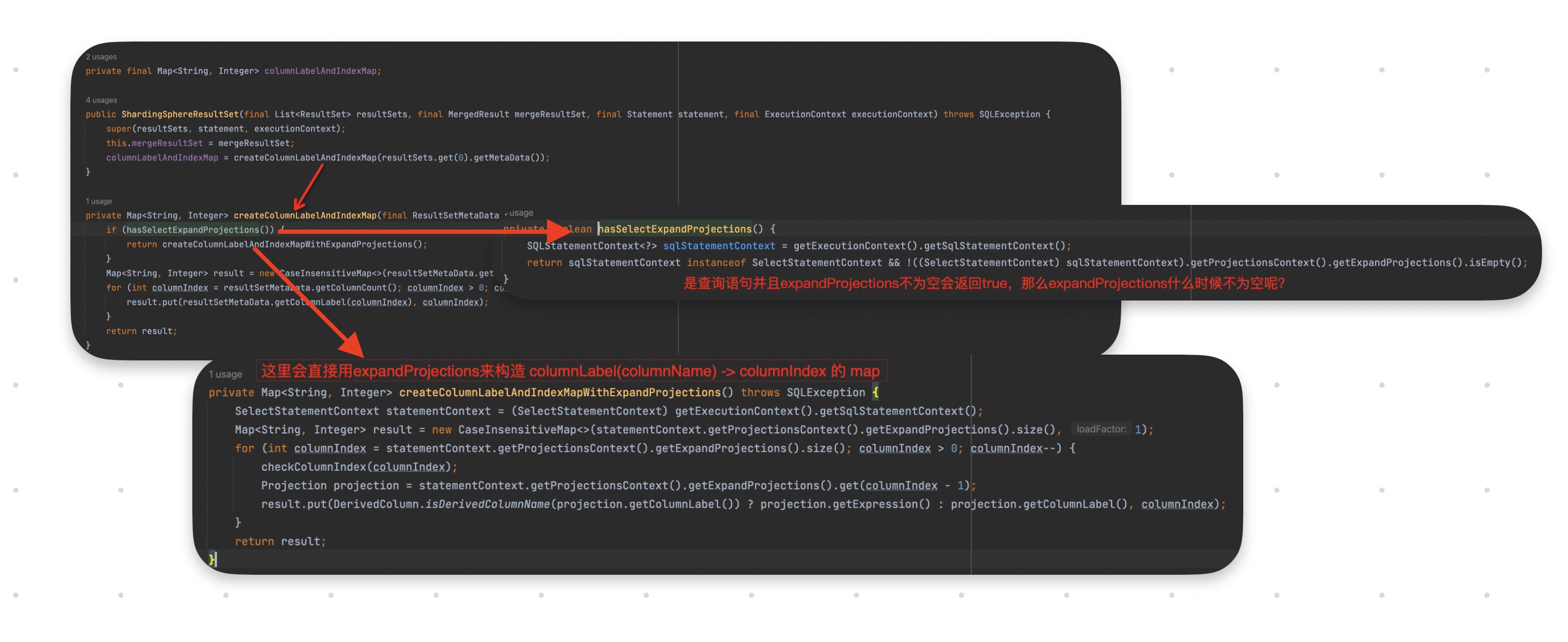
要搞清楚什么是expandProjections,我们先要搞清楚什么是projection。projection中文叫做投影,在shardingsphere的语境下其实是查询字段的意思,也就是SQL语句里跟在select后面的字段,每一个字段就对应一个projection。而*就是一个特殊的projection,在shardingsphere里被称作ShorthandColumn。expandProjections主要就是针对*这个字段,在expandProjections里会把*“展开”并“翻译”成所有字段。
prepareStatement(ShardingSpherePreparedStatement)
我们继续跟踪
expandProjections以及如何取到某张表的全字段,于是我们定位到了prepareStatement阶段(ShardingSpherePreparedStatement)
最终上面的方法的返回值result会被add到ProjectionsContext的projections列表里。可以看到,表的全字段是通过
schemas.get(schemaName).getAllColumnNames(tableName)来取到的。那schemas又是怎么维护的呢?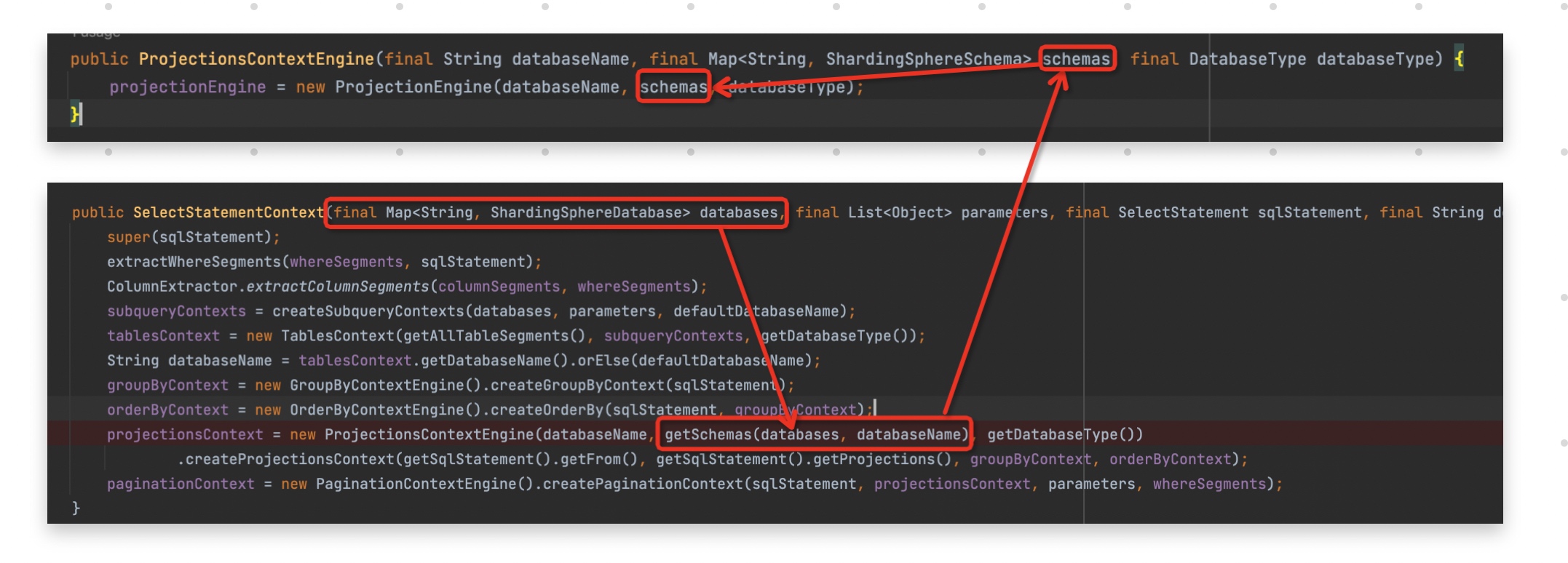
getSchemas(databases, databaseName)这个方法就是从databases这张map里面取出以databaseName为key的ShardingSphereDatabase,并调用它的getSchemas()方法获取这个数据源下面的所有库信息。库信息里包含所有表的表结构信息。那我们继续看看
Map<String, ShardingSphereDataSource>是怎么维护的,这个是一切的源头。这次我们跟踪到了shardingsphere-jdbc-core-spring-boot-starter的AutoConfigurationshardingsphere-jdbc-core-spring-boot-starter
shardingsphere-jdbc-core-spring-boot-starter里包含了自动配置类org.apache.shardingsphere.spring.boot.ShardingSphereAutoConfiguration,这个类在容器启动的时候会根据配置采用相应的模式去创建ShardingSphereDataSource。我们配置的是cluster模式,用zookeeper做治理中心。整体的调用链路如下
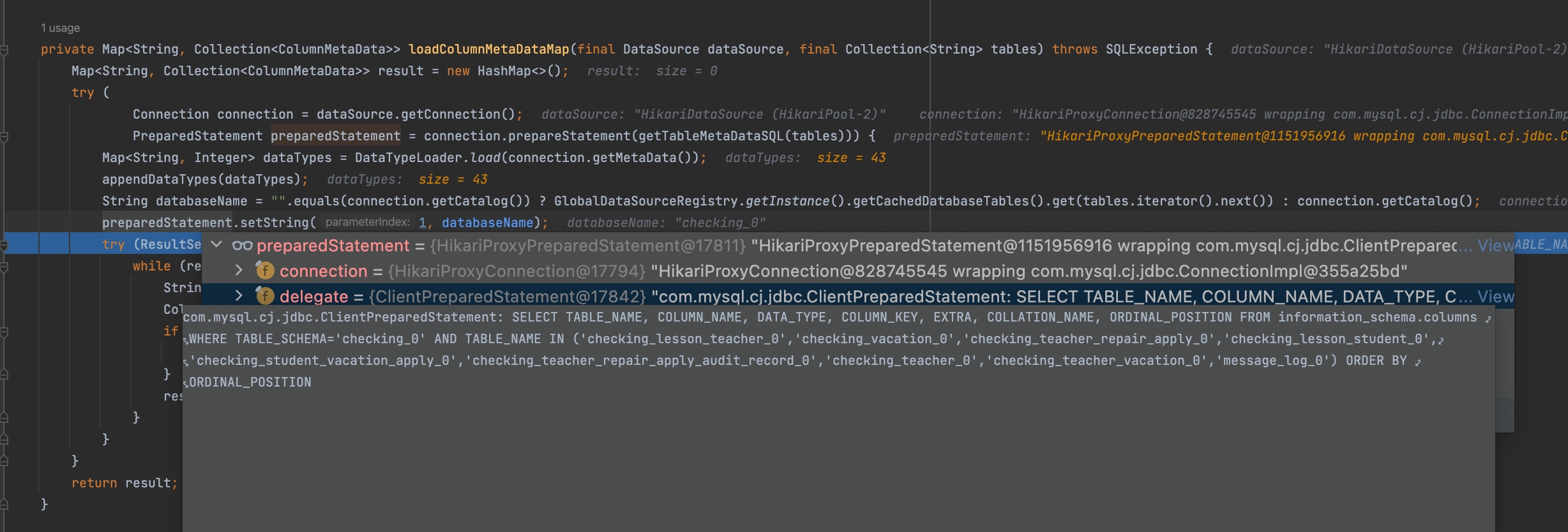
创建ShardingSphereDataSource的时候,会根据配置的库名创建对应的ShardingSphereDatabase。创建ShardingSphereDatabase的时候,还会构建整个库对应的表结构信息。

这个方法内部会拿到对应逻辑库的所有表,并从实际的物理库得到查询对应的表结构信息(字段信息、索引信息、约束信息等),并缓存。下面只截图了获取表字段的相关代码。
分析总结
至此,我们总算摸清了来龙去脉。这里再总结一下:
- shardingsphere-jdbc的自动配置会在SpringBoot启动的时候创建ShardingSphereDataSource作为容器内的主数据源
- 创建过程中会构建逻辑库、并维护所有逻辑表的表结构信息到内存中
- ShardingSphereDataSource.getConnection()会创建ShardingSphereConnection,这个connection上面会关联shardingsphere体系内的很多对象,并且通过prepareStatement()方法创建出来的是ShardingSpherePreparedStatement
- 创建ShardingSpherePreparedStatement的时候会解析传入的sql,对于
select *这类查询,会通过第1步维护在内存中的表结构信息,把解析成那张表的所有字段保存在expandProjections
- ShardingSpherePreparedStatement.execute()或executeQuery()方法产出的resultSet是ShardingSphereResultSet类型,创建ShardingSphereResultSet的时候会根据要查询的字段构造出
columnLabel->columnIndex的映射关系
- mybatis在查询结束,做字段映射的时候,会先从result set里取出对应字段。在通过getXxx(columnLabel)取值的时,要先把columnLabel转化成columnIndex,然后调用getXxx(columnIndex)获取对应的值
- 取到对应字段值后,再根据配置的实体类的字段,反射到实体对象里
而此次发生的问题就出在:我们修改了表结构,在表的中间位置增加了一个字段。而应用程序没有感知,ShardingSphereDatabase维护的表结构缓存还是旧的。导致在把
select *转换成全字段的时候是少了新增字段的,所以在维护的columnLabel->columnIndex的映射关系里,位置在新增字段之后的字段的index全部都比实际的小了1。所以resultSet.getByte("generate_type")实际取到的是upd_tm字段的值,所以就报出了前面的异常是bug吗?
这是个bug吗?我认为算是,感觉设计上不太合理。
虽然我找到了更新内存表结构的地方

因为我们用的是集群模式,通过shardingsphere-proxy执行表结构变更的时候,会更新zk的节点。应用监听zk节点的变更,会同步更新内存表结构。
但是这个修改点着实不太好找,因为修改schemas是直接通过getSchemas然后往map里put的方法,没有办法直接call hierarchy。
但是,如果说zk监听有点延迟的话,就有可能造成一段时间都会出现上面的问题。并且,上面是字段类型刚好没对上,如果说字段类型能对上,但是错位了,是不是会造成更恶劣或者更诡异的影响呢?
为什么不走shardingsphere-proxy更新?
因为这个逻辑数据库里其实既包含了shardingRule,也有singleTableRule,而我们这次要改结构的表是属于singleTableRule的表,所以我们常规就直接在物理表上修改表结构了
如何规避
- 不使用
select *,这样就不会用到内存表结构来获取表的全字段,从而能避免这个问题
- 使用shardingsphere-proxy更新表结构,但是前面我也说了,如果是zk监听有延迟的话,还是会影响一段时间
- 增加字段时不要加到中间,加到最后,这样也不会造成位置错乱
拓展
我们再来探究一下,如果没有使用shardingsphere,那么流程是怎么样的呢?
一般来说,都会有一个数据库连接池。比如我们用的是tomcat-jdbc,这个是
spring-boot 1.x时代默认的数据库连接池。那么容器里的主数据源就是org.apache.tomcat.jdbc.pool.DataSource。常规的sql执行还是那么几步:- 获取数据库连接,DataSource.getConnection()
- 创建statement,connection.prepareStatement(sql)
- 执行查询,statement.execute()
- 获取resultSet,statement.getResultSet()
- 遍历resultSet,并根据mybatis配置的映射,把resultSet里的记录转换成实体对象
可以看到,整体流程和前面使用shardingsphere-jdbc是一样的,只是说实现类不一样,从这里也能感受到Java语言和面向对象的魅力,也能感受到从普通数据源切换到shardingsphere的丝滑。前面提到了,对于mysql驱动的ResultSet来说,resultSet.getXxx(columnLabel)也是通过把columnLabel转换成columnIndex来实现的。但是这里是怎么转的呢?其实每一个查询语句,都会返回一个叫metadata的数据结构,里面包含了所有返回字段的元数据信息,所以这个一定是和返回结果能一一对应的,可以简单理解成“表头”。
总结
看似只是一个不大不小的问题,但是细究起来,知识密度和广度还是很大的。要把整体能串起来也没那么容易,这篇文章大概也是花了好几天才写好。
参考
- Author:黑微狗
- URL:https://blog.hwgzhu.com/article/shardingsphere-schema-cache-error
- Copyright:All articles in this blog, except for special statements, adopt BY-NC-SA agreement. Please indicate the source!
