type
status
date
slug
summary
tags
category
icon
password
AI summary
现象
当时是一个新上的业务表需要导入一批初始化数据,并且这张表是有通过canal-adapter实时往ES同步的。但是,当表里导入了330条数据之后,在ES里只发现了其中的14条(非同步延迟)。
分析
第一时间先查看了canal-adapter的日志,发现该表的同步链路有较多的报错信息:

截图里的异常信息看起来似乎也很明确:es里配置的studentJson是个object字段,但是创建文档时,该字段的值被设置为了一个“具体的值”,也就是并非object的结构。
但是通过了解,这批次导入的330条数据的studentJson字段都为空,不应该会有这个问题,并且成功了14条数据,这又怎么解释呢?
这个时候具体的开发同学又提供了一个信息:这条同步链路是昨天晚上上线的,刚上线的时候配错了。配错的就是上面的studentJson字段:es里配置的是object字段,但是在canal-adapter.yml里没有标注它是object类型的,发现之后就手动修正了。开发推测可能是这个原因导致的。推测归推测,怎么证明呢?
我们又从日志里找到一些新线索
线索1
原来异常信息并不是导入数据的时候才出现了,在昨天上线之后就一直有异常

线索2
同步到es的bulk请求的body大得有点诡异
(这张图没有太多了信息点,只是为了突出一个多而乱,可以尽量不看,容易头晕)

线索3
这个bulk请求的body是从报错开始一步步慢慢增大的

这张图的信息量很大,可以看到,bulk请求体貌似没有被清空,前面失败的请求一直在被滚雪球滚到后面的请求里。可以想象,第三次的bulk请求体里除了新的更新记录还会包含1,2,3这3条记录的更新体。这就解释了线索2说的bulk请求的body大得有点诡异的问题了。
bulk请求为什么这么大?
那为什么会出现这个问题呢?翻看了一下源代码,其实你很容易就理解了。下面这一段是commit bulk的代码:
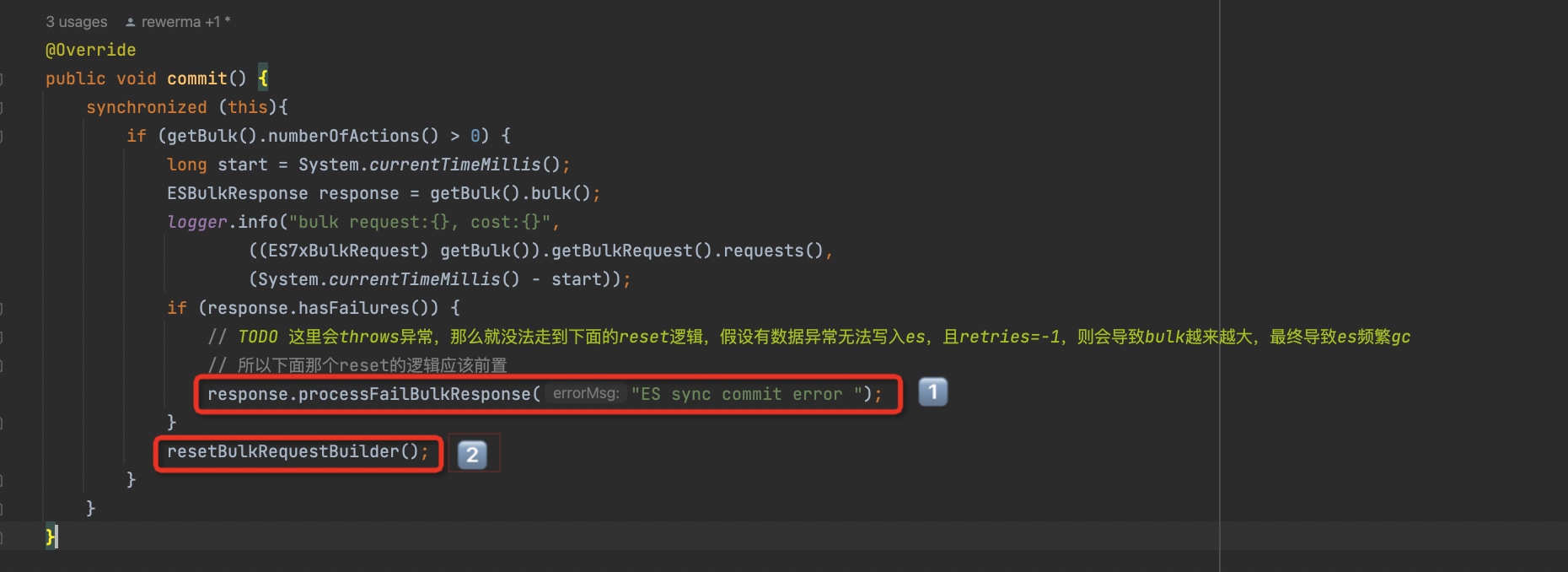
可以看到,提交bulk请求之后主要动作就2个:
- 如果存在异常,则要先处理异常,对应1️⃣处的代码
- 要重置bulk请求体,对应2️⃣处的代码 而问题就出在处理异常的代码里,因为其中可能会抛出异常,这样就无法走到2️⃣的代码,导致bulk请求没有被重置,从而越来越大 可以看到,只要错误的状态码不是NOT_FOUND,就会抛出异常。
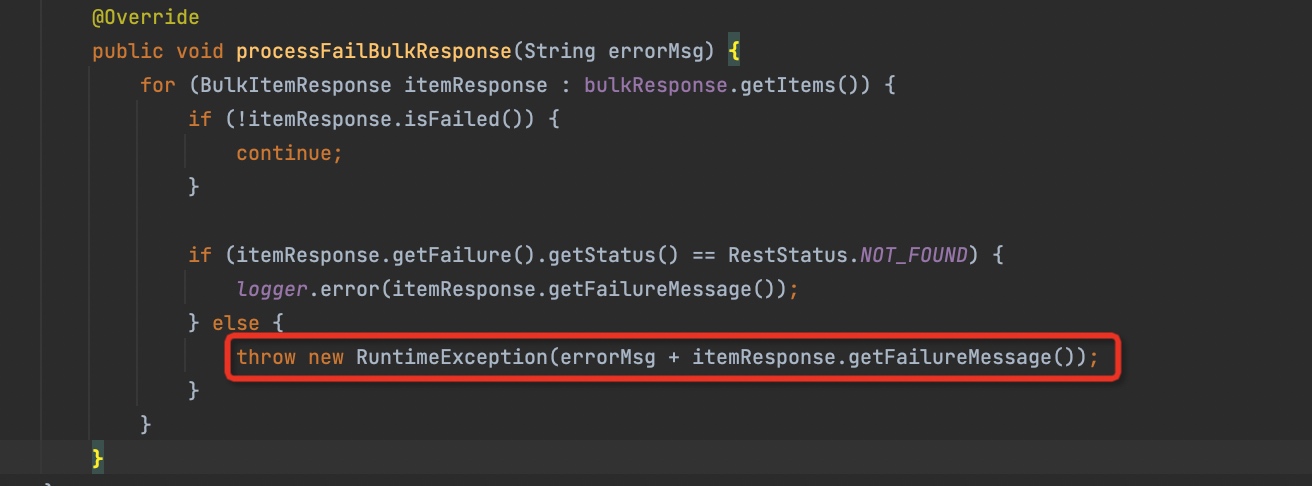
至此我们搞清楚了为什么前面bulk请求的body巨大的问题。但是为什么330条数据成功了14条呢?看来我们还得继续往下找答案。
为什么插入的330条数据只成功同步了14条?
我们先尝试从canal-adapter的日志里看看能不能捞到成功同步的数据,和实际es里的数据能不能对得上
2台机器上,刚好总共14条数据。并且和同步到es里的14条数据吻合。到这一步至少我们证实了:这14条数据确实是由canal-adapter同步过去的,并且也只同步成功了这14条。
那么为什么就同步了这14条数据呢?看来需要跟进其中一条链路来分析一下。


可以看到,虽然从kafka获取了N条消息,但是只处理了第一条,并且在处理第一条的时候报错了,所以导致后面的消息都没有处理到。
这里铺垫一个知识点,canal-adapter数据同步的核心流程是先从mq里拉取一批消息,然后依次处理每一条消息里的每一行数据变更。而对于同步es的插件,因为走的是bulk请求(可以理解成批量请求,单条数据变更只是添加到一个队列里,当队列达到一定的数量或者满足一定的时间条件才会提交),所以每处理完一条数据变更,都需要判断一下有没有达到提交bulk的阈值,如果到了,就会直接提交。下面以insert为例,我们展示一下代码:
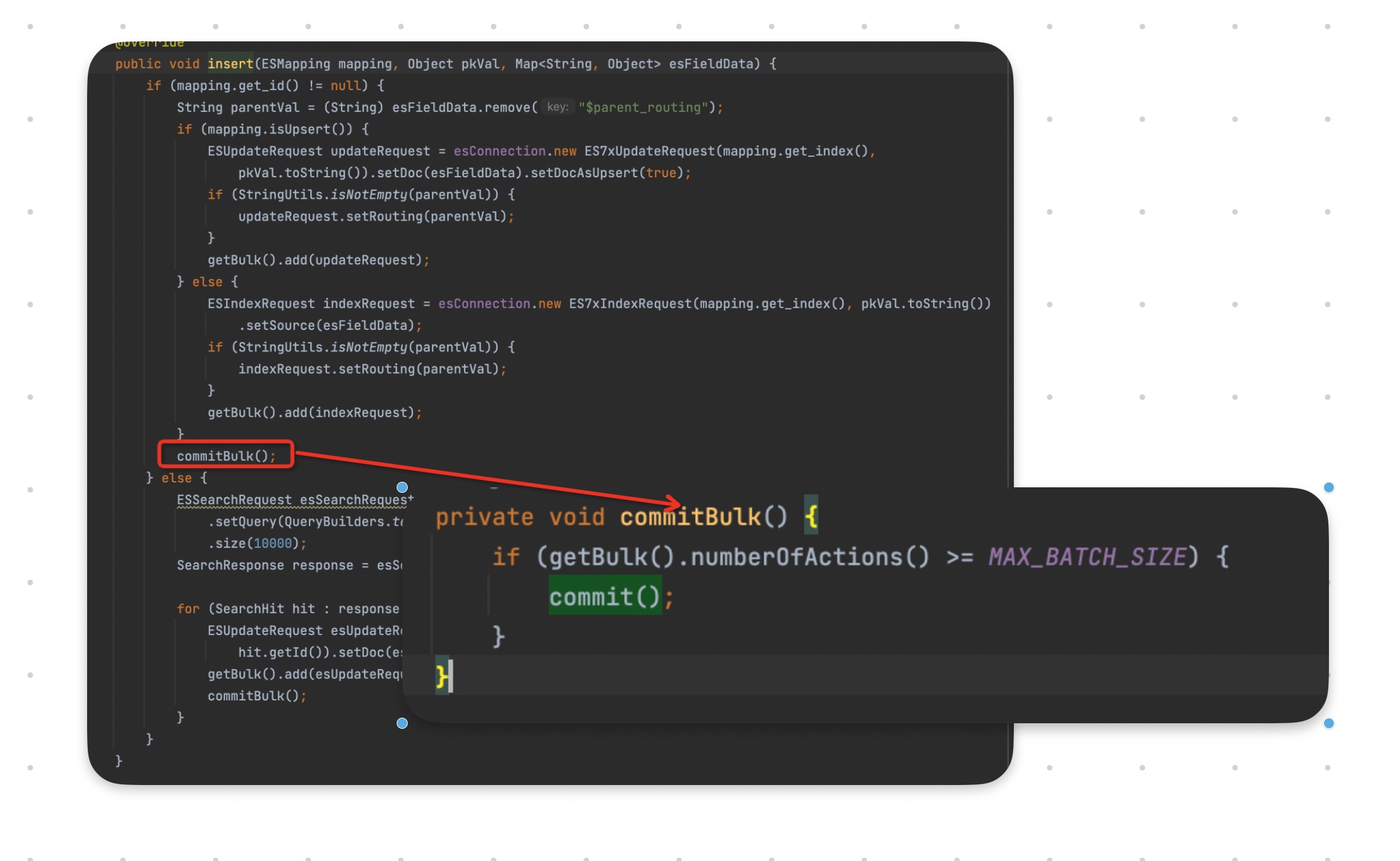
而刚好由于前面的问题,导致bulk里的请求量已经非常大,超过MAX_BATCH_SIZE了,所以后续的每一行数据变更,都会导致bulk请求的提交。提交之后就报错了,这样如果一次拉取了10条消息,其实只处理了其中1条,然后就提交了bulk请求,报错了,于是后面的9条消息也得不到机会处理,只能等待下一次拉取消息了。
至此我们搞清楚了为什么330条数据只同步成功了14条
新的疑问
不过这里我又发现了一个新的疑问:因为我们配的重试次数是10次,也就是说,canal-adapter在消费到一批消息报错时,它会重新去mq拉取消息再消费,重试到10次之后,会直接commit。

但是注意,上面的消息数量是不是很奇怪。按照正常的理解,重试的情况每一次拉取到的消息的数量应该不会少于之前的量。但是为什么上面的日志并没有体现出这一特征呢?难道是回滚时有什么骚操作?我们来看看代码:
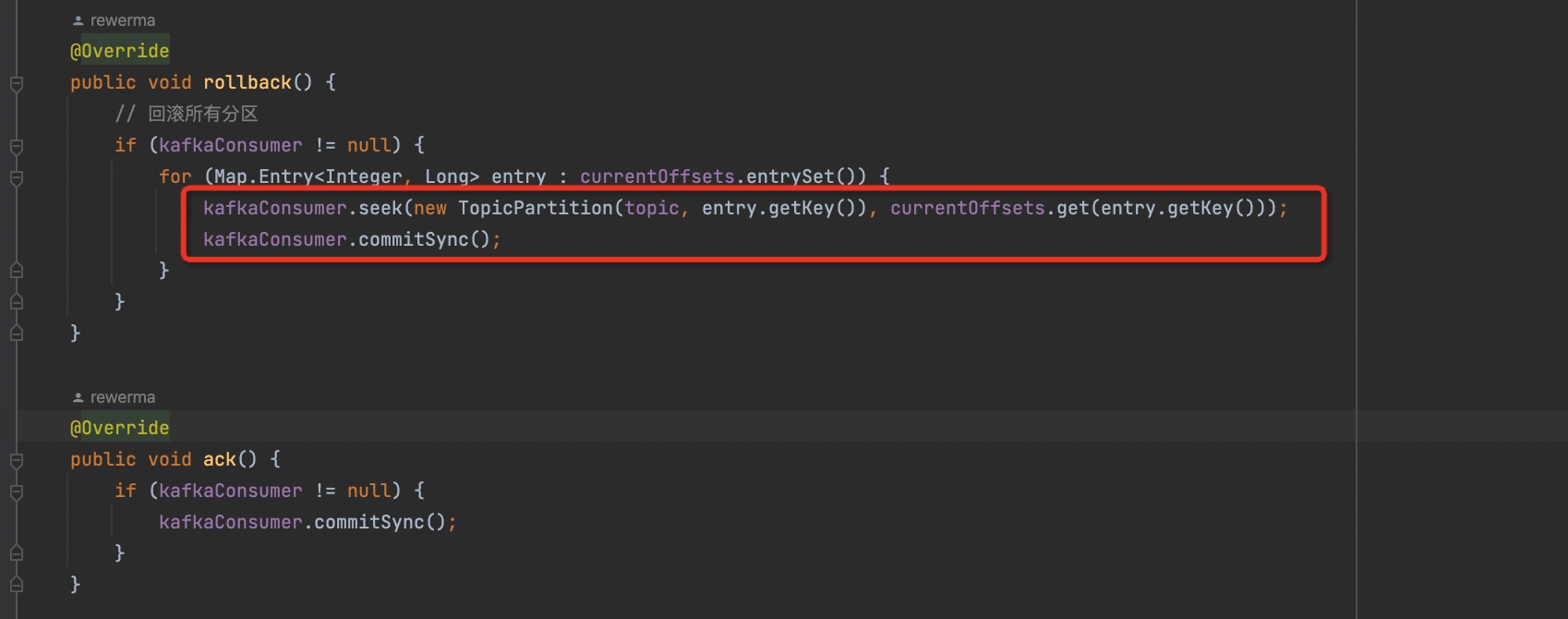
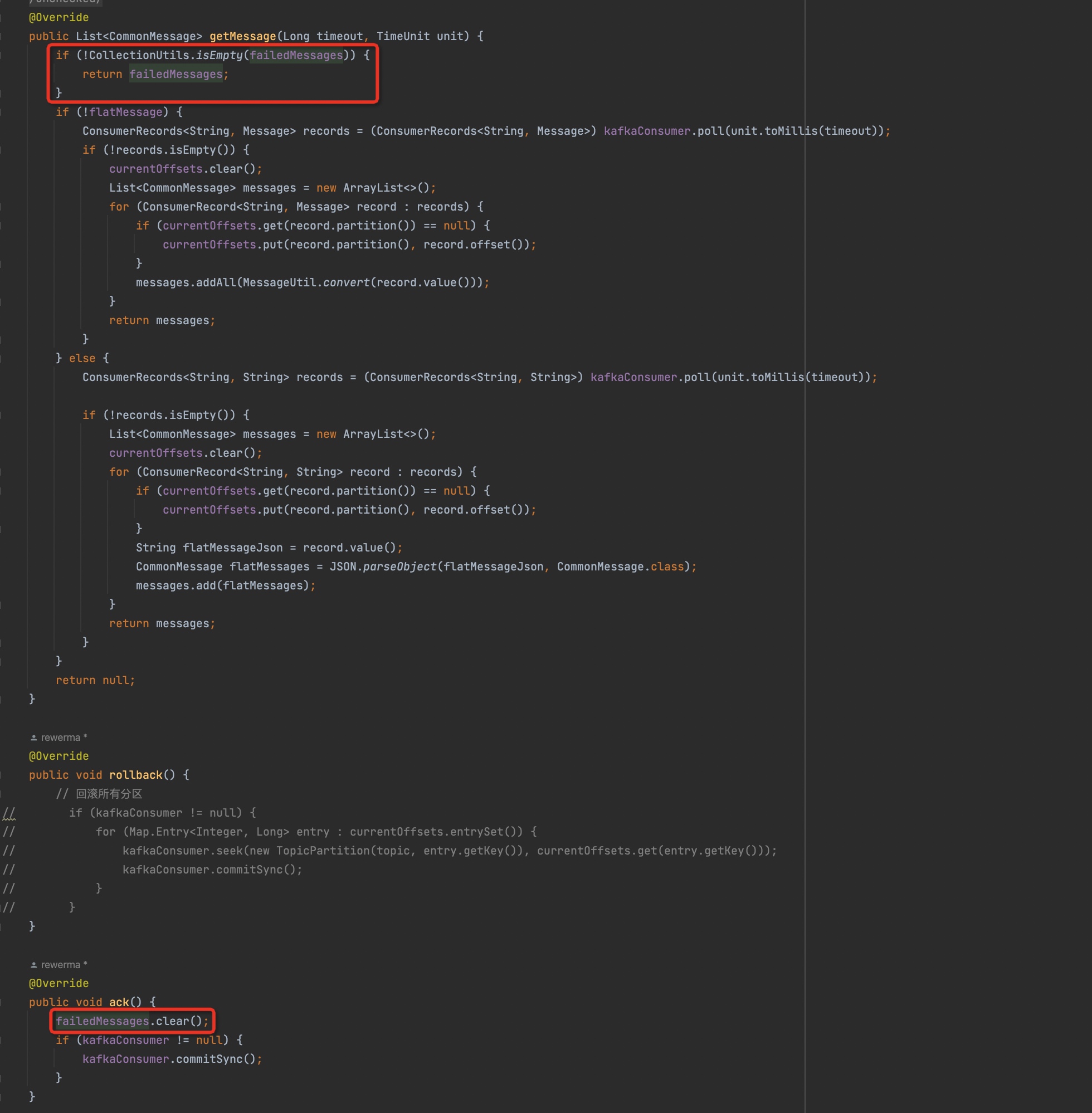
确实和我想得不太一样,我原以为rollback里面应该是空实现,啥也不用做,因为我们配置autocommit=0,所以不手动commit的话offset应该是不会被提交的。那么这里为什么要用seek呢?
这里我去了解了一下kafka的poll机制:原来kafka的poll,会把自身内存里的offset改变掉,虽然broker里的offset没变,但是我自身下一次去拉的话是会从上一次poll完后的offset再去poll。所以这里用了一个seek来人为的“还原”offset。但是为什么要调用
commitSync方法呢?我认为应该是一个bug,因为- 此时不需要去改变broker上记录的offset
- 注意,这里是每seek一个partition就会调用commit把所有的partition的offset都提交到broker上。这样一来问题就更严重了。比如我把partition1 seek到了老的offset,但是其他partition已经是最新的offset了,这样一commit那其他partition就会被更新成最新的offset。虽然最后都会更新成最老的offset,但是多了很多中间态,可能会造成一些意想不到的问题。比如突然宕机了,那么消息就丢了。
但是虽然有上面的问题,但似乎还是没有解释到为什么后一次消费到的消息竟然会比前一次要少的问题。于是我们进一步的去看了poll的源代码,整理出了下面这幅流程图
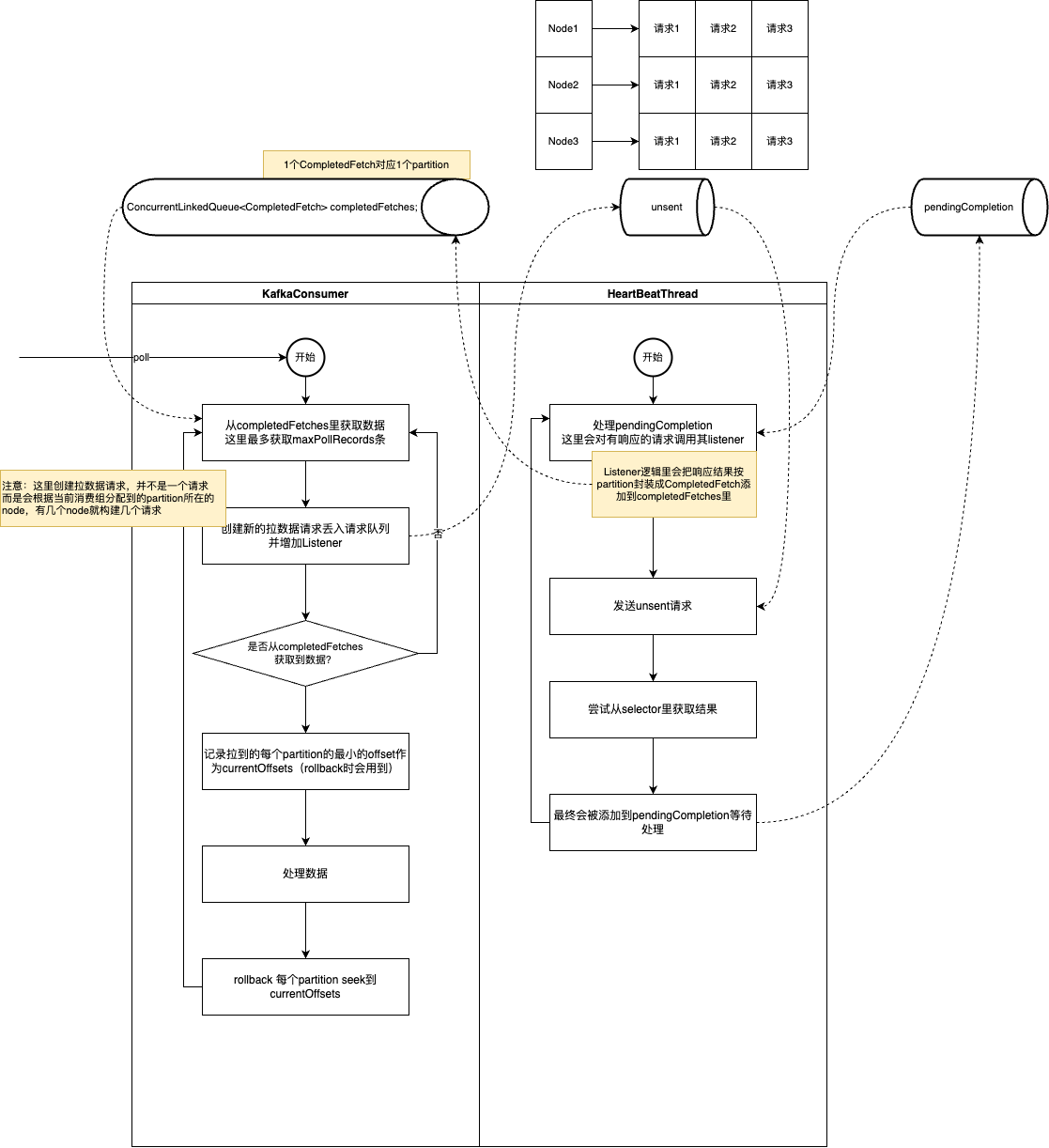
从图上我们可以看出,整个流程并非我们原以为的,每次poll的时候才会向broker发起请求。其实poll主要处理的是已经从broker响应的请求(completeFetches),并构建向broker发起的请求内容丢到一个队列(unsent)里。而构建请求的时候会根据本机分配到的partition所在的broker来构建,也就是说关联到几个broker就会构建几个请求入队。而真正向broker发起请求的是HeartBeatThread。所以整个过程其实是个典型的生产者-消费者模式。
在这个“全新的”理解之下,似乎上面的结论就是错误的。比如,我本机分配到了4个队列,并且位于3个broker上,这个时候3个请求可能都不一定是同时响应的。那么调用poll方法在处理的时候,有可能需要调用3次才处理完,每次都处理的是某1个broker的响应结果。
并且,更进一步,对于消费失败重试的机制来说。理论上应该保证每次重试的内容是一样的,而对于canal-adapter当前的重试机制来说,每一次拉取的数据可能都是不一样的,比如第10次才拉到的消息,其实只执行了一次就不会重试了(如果结合上面说的场景那就更差劲了)。这里我们尝试优化一下这个机制,我们把每次拉到的消息缓存起来,消费成功了再清掉,否则就一直处理这一批请求直到达到最大的重试次数。(这样似乎也更符合kafka会把本地内存的offset往前推进的设计理念)
总结
可以看到,排查这个问题的过程还是挺曲折的:我们依次排查了“bulk请求为什么这么大”、“330条数据为什么只同步了14条”、“kafka poll机制”以及“canal-adapter kafka消费者 消费异常处理”这几个问题。这些都是由“330条数据为什么只同步了14条”引出的。并且“bulk请求超大”这个问题的其实远比想象中更严重,因为bulk过大有可能会引起的2个问题:1是应用的内存溢出,2是造成es的压力。这个都可能会对线上业务造成非常严重的影响。
另外,在了解“kafka poll机制”的这个过程中,其实我们最初的猜想是“有没有可能是timeout引起的,poll的机制会不会是取数据取到timeout条就返回了”。后面我们也了解到了,一次poll的数据还和fetch.max.bytes(去broker拉数据的最大数据量)、max.partition.fetch.bytes(单个partition拉到的最大数据量)和max.poll.records(一次poll的最大数据量)有关系。前两个和请求broker相关的,最后一个是和poll相关的。
在排查1个问题的同时,往往会带出不少新的问题。但是每个问题的背后都代表着你对于这一块知识点的缺失。能借由线上问题来补充我们的知识漏洞,我想这应该是提升最快的方式了吧。
- Author:黑微狗
- URL:https://blog.hwgzhu.com/article/canal-adapter-sync-data-uncompleted
- Copyright:All articles in this blog, except for special statements, adopt BY-NC-SA agreement. Please indicate the source!
Relate Posts