
type
status
date
slug
summary
tags
category
icon
password
AI summary
现象
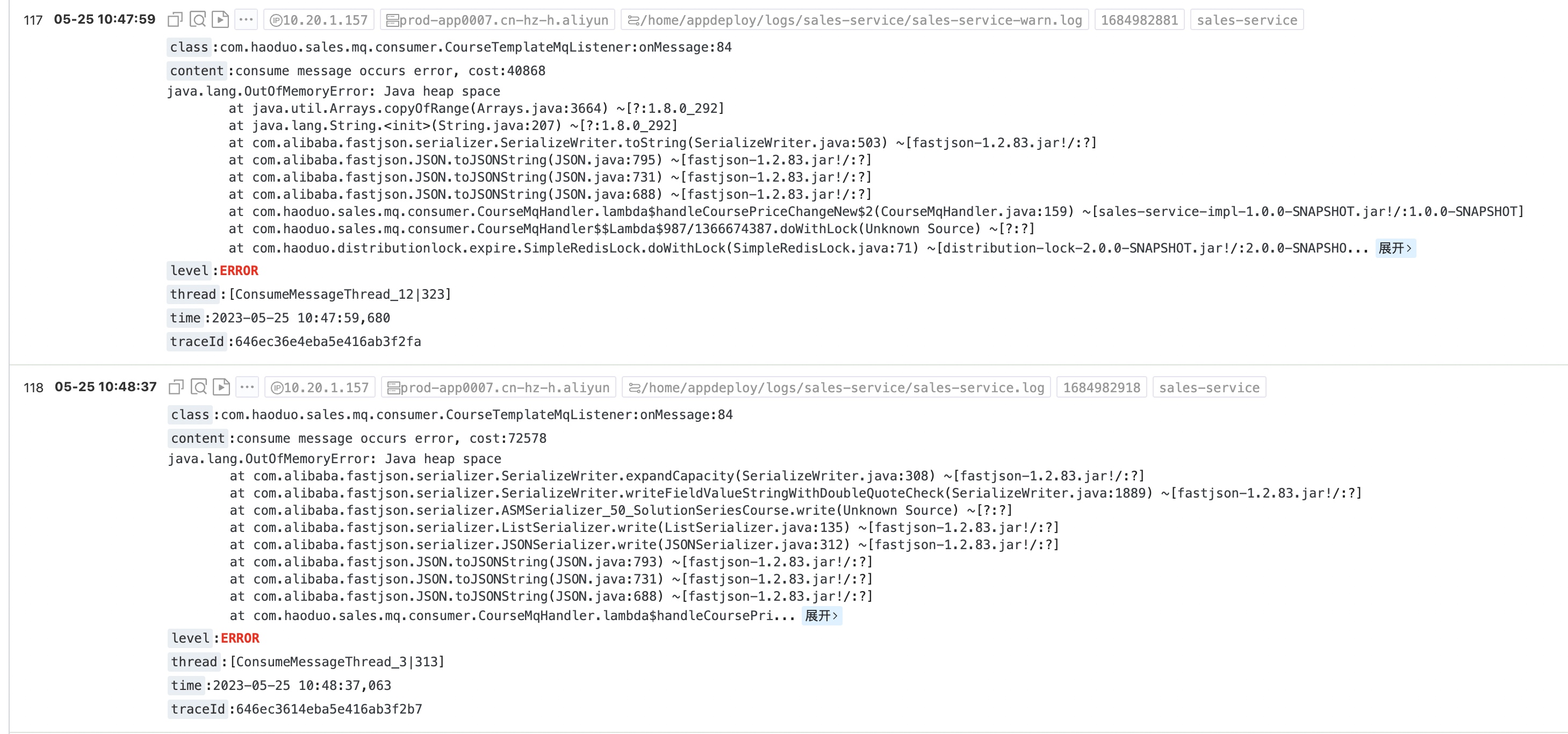
5月25上午线上某个服务开始有OOM的报错日志出现,于是开始定位问题
处理过程
分析
我们的应用都有配置OOM会自动dump内存,所以直接下载dump文件进行分析。关于如何用mat分析内存dump,这里推荐2篇文章可以快速入门(JVM 内存分析工具 MAT 的深度讲解与实践——入门篇、JVM 内存分析工具 MAT 的深度讲解与实践——进阶篇)
先看下dominator tree,翻译过来也叫支配树,关于支配树,下面这个图的示例非常有助于理解(也是从上面2篇文章里面直接搬运过来的哈)。
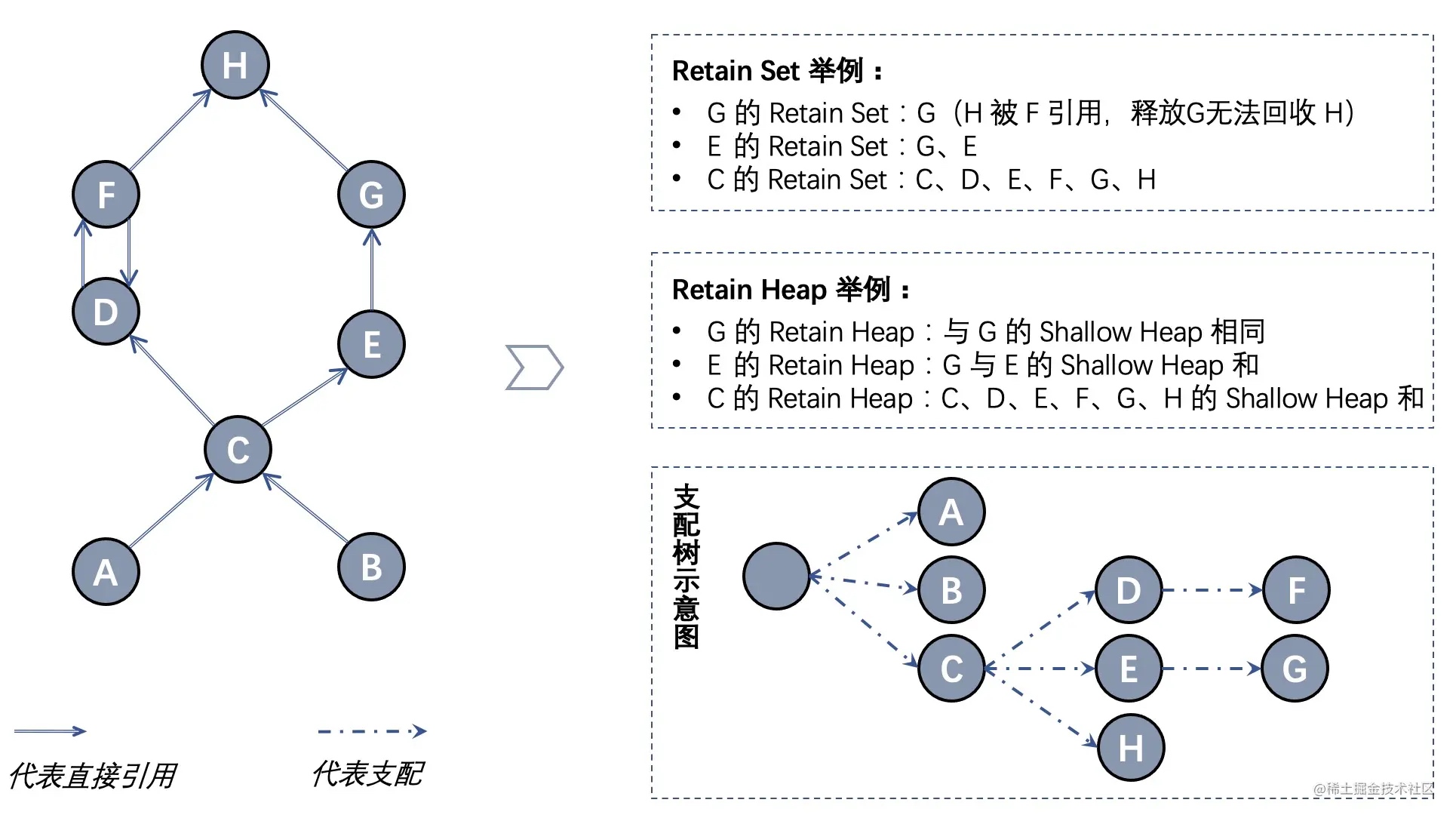
如果所有指向对象 Y 的路径都经过对象 X,则 X 支配(dominate) Y(如上图中,C、D 均支配 F,但 G 并不支配 H)。Dominator tree 是根据对象引用及支配关系生成的整体树状图,支配树清晰描述了对象间的依赖关系,下图左的 Dominator tree 如下图右下方支配树示意图所示。支配关系还有如下关系:
- Dominator tree 中任一节点的子树就是被该节点支配的节点集合,也就是其 Retain Set。
- 如果 X 直接支配 Y,则 X 的所有支配节点均支配 Y
下面我们就看看当时的支配树:

按照retained heap排序之后,很容易能看出靠前的几个支配链可能是有问题的。这几个大的支配链可以被分成3类:
- log4j2 AsyncLogger的RingBuffer
- ConsumeMessageThread RocketMQ某个消费组的消费线程
- Log4jThread Log4j2 AsyncLogger打印日志的消费线程
我们按顺序展开看看,先看RingBuffer
RingBuffer
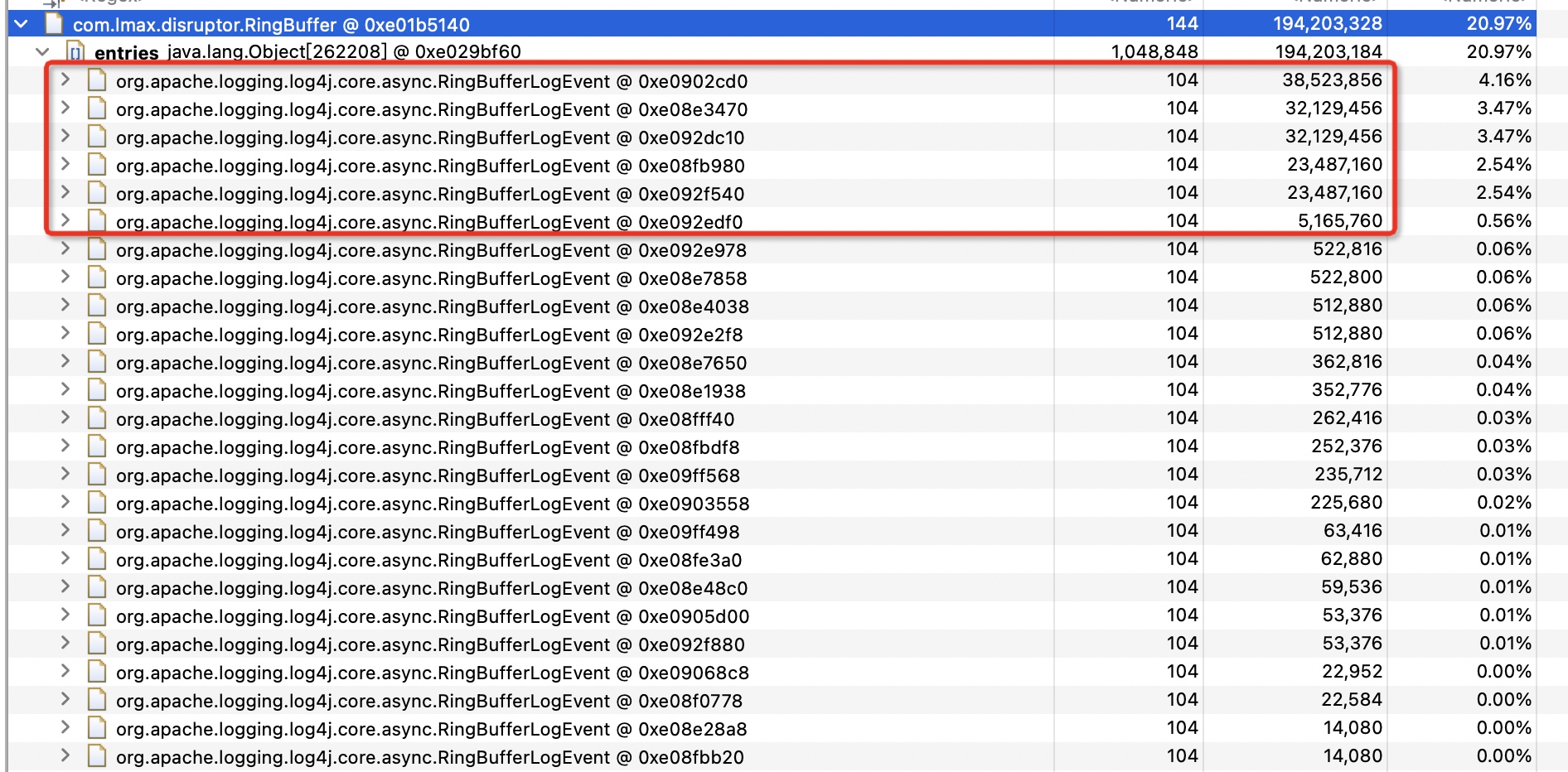
这个RingBuffer是log4j2 AsyncLogger的缓冲区,我们可以看到,单个日志事件已经达到了30多M。这个肯定有问题的,这么大的单行日志,内存不爆了才怪。看了下内存占用较高的都是在同一处代码的日志输出。

ConsumeMessageThread
我们接着看其他的大内存占用对象

上面的4个大对象我已经用红字标注了源代码中对应的对象。
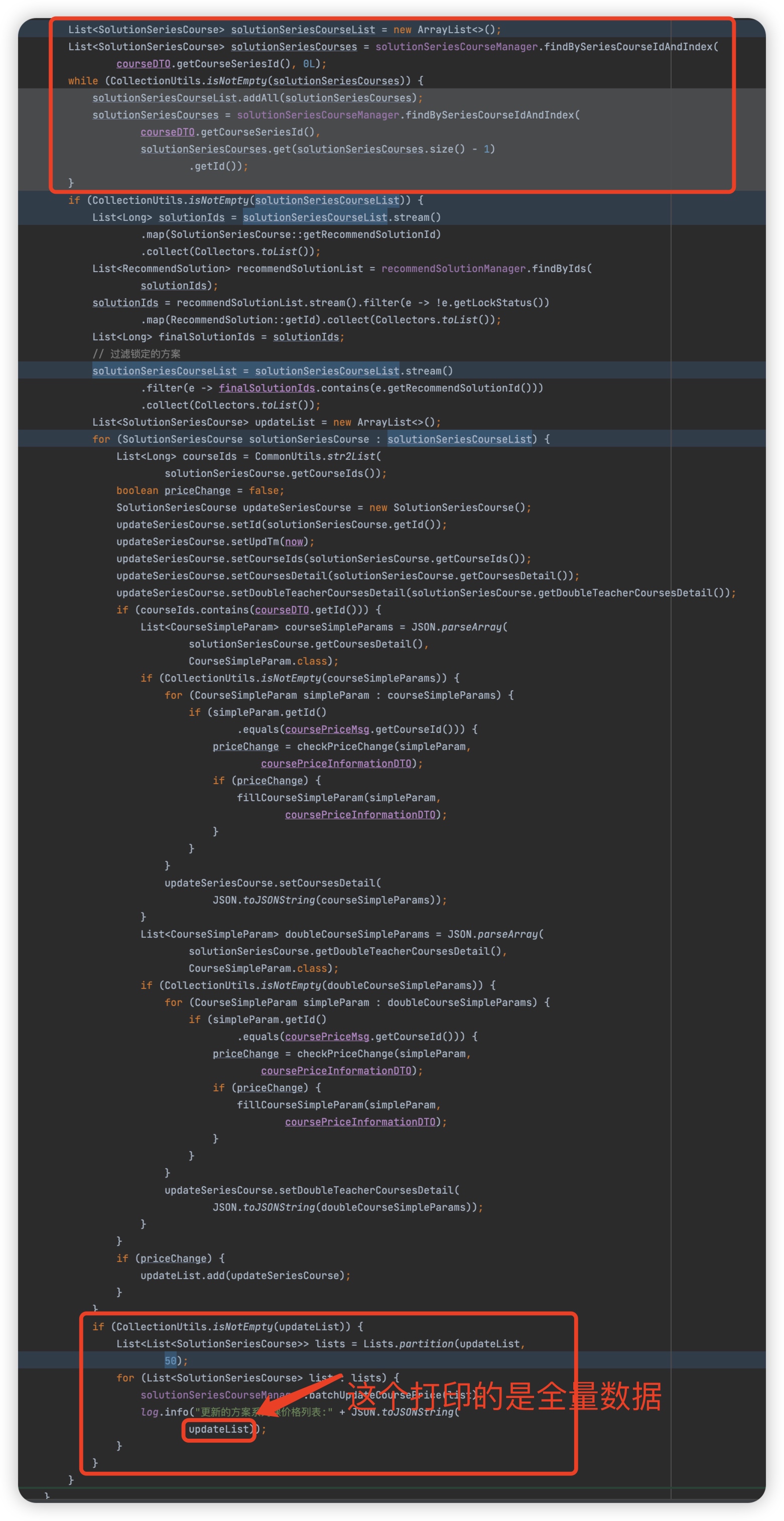
上图的代码逻辑简单总结一下
- 分页查出全量的solutionSeriesCourse放入
solutionSeriesCourseList(在这个消费线程里有3898条记录)
- 拿到每个solutionSeriesCourse的recommendSolusionId组成一个solutionIdList,去对应recommendSolusion表里查出对应的记录,得到变量
recommendSolutionList
- 构建更新
solutionSeriesCourse表的实体对象列表,updateList
- 最后分批次批量更新
但是从代码上我们不难看出一些性能隐患:
- 虽然通过minId的分页查询在一定程度上减少了深度翻页慢查的问题,但是没有考虑数据量过大导致的OOM的问题,并且这张表的字段里面有json相关的大字段
- 最后虽然是分批次更新的,但是在每次批次里打印的日志并不是单个批次的更新日志,而是全量的更新日志。并且此处更新了json字段,就导致了日志事件非常大
Log4jThread
Log4jThread是Log4j2 AsyncLogger里的日志事件消费线程,主要负责打印

这个线程里的这个大StringBuilder对象应该就是通过正在处理的RingBufferLogEvent构建出来的,足足占用了100M+的空间。
之前的截图里其实已经包含过这个RingBufferLogEvent了,它有一点特殊,是直接以独立的支配链出现的
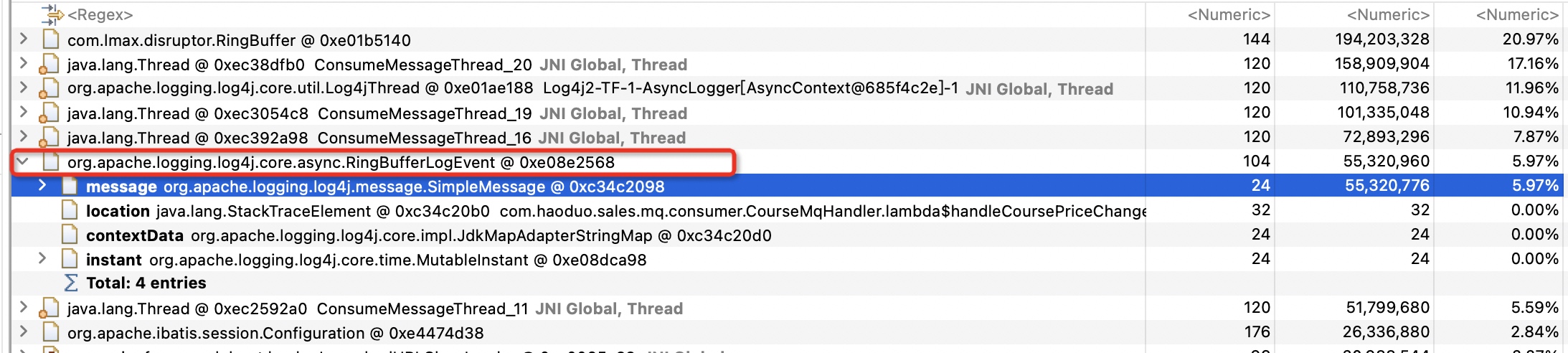
为什么是以独立的支配链出现的呢?因为引用这个对象的地方不止RingBuffer一处,Log4jThread也引用了,任何一处释放了都无法直接释放它,所以它是独立的。这个我们也可以通过inbound列表来证明:

但是细心的你是不是发现了,2者占用的内存空间差了有将近一倍。RingBufferLogEvent占用50M+的内存,而StringBuilder对象占用了100M+,这是为什么呢?
因为StringBuilder内部是一个字符数组,在append的时候有自动扩容的逻辑,默认会扩充到1倍+2的大小。所以应该是扩容导致的,实际使用的空间并没有那么多,浪费了不少。
解决
到这里,其实问题已经分析的差不多了。我们知道问题的原因主要在于
- 查询了全量的solutionSeriesCourse数据到内存
- 把全量的更新对象序列化并打印出了日志
所以解决的方案主要就是针对这两个问题:
- 我们每批次查询100条数据,并处理。处理完一批再去查询第二批,直到处理完为止
- 只打印更新批次的日志
总结
在监听MQ做大批量数据变更的时候,一定要考虑内存溢出的问题。尽量运用分批处理的思想,因为既然通过MQ做异步处理了,那么对于时间的敏感度理论上是不高的。这里追求的不是速度,而是稳定性。并且如果需要处理的数据量很大,更加无法做到对时间敏感。这个在设计方案的时候都要评估到位。
- Author:黑微狗
- URL:https://blog.hwgzhu.com/article/online-oom-problem-analyze-and-solving
- Copyright:All articles in this blog, except for special statements, adopt BY-NC-SA agreement. Please indicate the source!
Relate Posts