type
status
date
slug
summary
tags
category
icon
password
AI summary
Sentinel之计数统计及限流核心逻辑
引言
上篇文章分析了Sentinel的4种限流器的实现。其中有3种限流器都用到了
node.passQps()去获取qps。本篇文章我们就基于这个来分析,看看这些个统计信息是怎么维护的。源码分析
Node
在我们阅读源代码之前,我觉得有必要先介绍一下Sentinel里面的各种Node(摘自官方文档):
StatisticNode:最为基础的统计节点,包含秒级和分钟级两个滑动窗口结构。
DefaultNode:链路节点,用于统计调用链路上某个资源的数据,维持树状结构。
ClusterNode:簇点,用于统计每个资源全局的数据(不区分调用链路),以及存放该资源的按来源区分的调用数据(类型为 StatisticNode)。特别地,Constants.ENTRY_NODE 节点用于统计全局的入口资源数据。
EntranceNode:入口节点,特殊的链路节点,对应某个 Context 入口的所有调用数据。Constants.ROOT 节点也是入口节点。
如果你是刚接触Sentinel,对于上面这些描述可能不是非常理解,没关系,有个概念就可以了,后面碰到的时候还会详细分析。
滑动窗口的统计
下面我们直奔源代码
com.alibaba.csp.sentinel.node.StatisticNode#passQps前面提到
StatisticNode包含妙计和分钟级两个滑动窗口,这里的rollingCounterInSecond就是那个秒级的滑动窗口。默认情况下,内部分成2个子窗口,500ms一个。passQps()就是滑动窗口上统计的请求数量除以窗口的长度(rollingCounterInSecond的窗口长度为1s)。我们继续看rollingCounterInSecond.pass():可以看到滑动窗口内的每个子窗口(
MetricBucket)上也都有计数,滑动窗口的计数就是把每个子窗口的计数汇总起来。滑动窗口的滑动
滑动窗口之所以称之为滑动窗口,说明它是动态的,会随着时间向前滑动的,我们看看它是怎么滑的:
首先根据当前时间计算其在滑动窗口里的位置idx,然后再计算这个子窗口的起始时间windowStart。再根据idx去取当前处于该位置的子窗口,最后比较新旧2个子窗口。总共存在4种情况:
- 旧窗口不存在,这只能是第一次访问的时候,此时我们创建一个新的子窗口(WindowWrap)对象并放入对应位置
- 旧窗口和新窗口的windowStart相等,代表是同一个窗口,无需切换
- 旧窗口的windowStart更小,说明旧窗口已经过期了,这种场景需要用新窗口的数据重置旧窗口
- 新窗口的windowStart更小,说明可能发生了时间回拨,这里虽然创建并返回了一个新的子窗口,但是并没有改变滑动窗口内的子窗口。所以,对于时间回拨,Sentinel使用了之前的窗口。但是为什么不能直接返回old呢?
我们回顾一下请求的执行链路:请求通过限流器时,先要调用
currentWindow()方法根据当前时间把窗口滑动到对应的位置,接着从滑动窗口上获取计数统计信息(qps或并发数),再结合本次请求要获取的permits判断是否通行。如果可以通行,我们还需要增加当前子窗口上的并发数和qps。SlotChain
这里再插入一段关于
Sentinel SlotChain的介绍,以便于你更好的理解本文。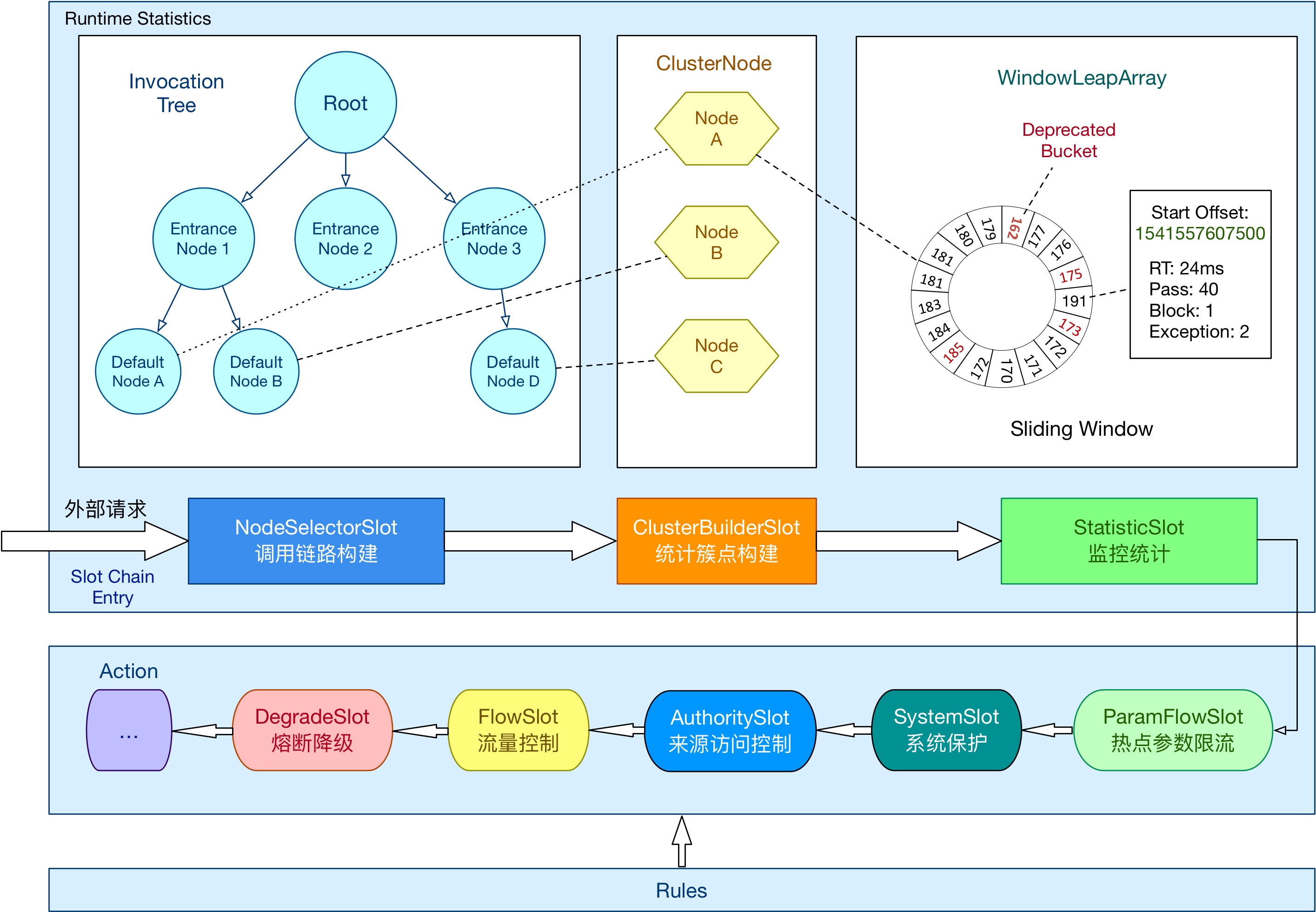
Sentinel是基于一系列的Slot组成的SlotChain来实现其限流降级功能的。这个Slot和SlotChain有点像我们常见的Filter和FilterChain,都是基于责任链模式设计的。下图列出了内置的一些核心Slot,后文我们会提到
NodeSeletorSlot、ClusterBuilderSlot、StatisticSlot以及FlowSlot另外,每个
resource对应1个SlotChain实例。而SlotChain内的Slot实例,对于多数的Slot都是单例的,只有2个例外:NodeSelectorSlot和ClusterBuilderSlot,这2个都是每个resource1个实例。滑动窗口上统计数据的维护
StatisticSlot
维护的代码在
StatisticSlot里:StatisticSlot里维护了三类Node:DefaultNode,由请求资源resource + 上下文contenxt共同决定。维护调用链路的请求数据。主要用于RuleConstant.STRATEGY_CHAIN这种限流策略
OriginalNode,类型为StatisticNode。维护调用方的请求数据。主要用于对调用方限流。不过前提是需要显式调用ContextUtil.trueEnter(String name, String origin)传入origin
Constants.ENTRY_NODE,类型为ClusterNode,只用于服务提供方,全局只有一个实例,维护应用级别的请求数据。主要用于系统自适应保护。
这三类Node分别用于不同的限流维度,上面也都有提到。下面我们就看看维护好的统计数据,是如何在限流时发挥作用的。
限流核心逻辑
限流相关的逻辑在
FlowSlot里,下面是调用链路,我们仅以单机限流为例进行分析。
限流核心逻辑总结
关于限流的核心逻辑这里我再总结一下:
- 根据请求的资源获取对应的限流规则列表
- 判断本次请求是否可以通过每个限流规则
- 根据规则和请求上下文获取限流维度
- 根据限流维度获取对应的统计节点
- 根据统计节点上的统计数据以及本次请求需要的
permits判断是否能通行
- 所有规则通过则请求放行,一旦不通过,直接抛出
FlowException
限流规则
这里列出了限流规则的一些重要属性,参考:官网介绍
Field | 说明 | 默认值 |
resource | 资源名,资源名是限流规则的作用对象 | ㅤ |
count | 限流阈值 | ㅤ |
grade | 限流阈值类型,QPS 模式(1)或并发线程数模式(0) | QPS 模式 |
limitApp | 流控针对的调用来源 | default,代表不区分调用来源 |
strategy | 调用关系限流策略:直接、链路、关联 | 根据资源本身(直接) |
controlBehavior | 流控效果(直接拒绝/WarmUp/匀速+排队等待/WarmUpRateLimit),不支持按调用关系限流 | 直接拒绝 |
clusterMode | 是否集群限流 | 否 |
refResource | 链路策略下代表场景名称或入口名称、关联策略下代表关联资源名 | ㅤ |
三种限流策略
其中对于限流规则的三种不同的限流策略我也做了一个总结,有助于更好的理解:
- direct策略:直接,最容易理解,只有三种场景
- 不指定调用方:对资源整体限流
- 明确指定调用方:对明确指定的调用方对资源的请求限流
- 指定other调用方:对未配置限流规则的调用方对资源的请求限流
- relate策略:可以把多个资源共享同一个统计信息,比如可以给a、b这2个资源配置relate策略,且refResource为c的限流配置,此时对a、b、c这三个资源的请求会共用统计信息。比如有3个接口都是对同一张表的访问,我们可以对它使用此策略来达到效果。不过此时a、b两个策略对于限流的阈值配置是可以不同的,请求也会根据原请求资源去匹配对应的配置,而资源c的请求并不会被限流
- chain策略:可以针对某一条链路限流,有链路的概念,那么请求的时候必须得有明确的context。context可以理解为入口、场景。那么此策略下可以对某些场景下对某些资源的请求做限流,而其他场景对此资源的请求不受影响
ClusterNode
ClusterNode上的统计数据是在哪里维护的呢?其实每个DefaultNode都会关联一个ClusterNode,并且在统计自身的时候也会把统计信息应用到ClusterNode上低开销获取时间戳
在分析滑动窗口代码的时候我发现关于时间戳的获取,Sentinel并没有每次都去调用
System.currentTimeMillis()。而是采用了“缓存”的形式,RUNNING状态下每毫秒更新一下:这种方式的意义在于提升性能,因为在高并发下,
System.currentTimeMillis()的开销较高。如果你感兴趣,可以看看这篇文章低开销获取时间戳关于时间回拨的思考
前文分析的时候,也提到了时间回拨:在滑动窗口滑动时,Sentinel对于时间回拨的策略是不处理,维持当前滑动窗口不滑动。这里我们再细想一下,假设真的发生了时间回拨,会造成什么影响。
我们极端一点,假设时间回拨了10分钟,这个时候这10分钟的请求都会用同一个滑动子窗口的统计数据。所以如果发生了时间回拨,那回拨之后到当前时间内的请求都会算在当前子窗口上,可能会造成一定的误限流。当然这里只看了回拨对这一条链路的影响,其他的点没有深入考虑。
参考
- Author:黑微狗
- URL:https://blog.hwgzhu.com/article/sentinel-statistics
- Copyright:All articles in this blog, except for special statements, adopt BY-NC-SA agreement. Please indicate the source!