type
status
date
slug
summary
tags
category
icon
password
AI summary
引言
最近在看限流相关的内容,那自然不能不看国内限流框架的翘楚——大名鼎鼎的Sentinel了。Sentinel相关的学习和分析将分为2篇内容来记录,本篇重点关注Sentinel实现的几种限流算法。
官方介绍
我们先看看官方介绍里针对限流这个模块的说明:
2.2 QPS流量控制 当 QPS 超过某个阈值的时候,则采取措施进行流量控制。流量控制的手段包括下面 3 种,对应 FlowRule 中的 controlBehavior 字段:直接拒绝(RuleConstant.CONTROL_BEHAVIOR_DEFAULT)方式。该方式是默认的流量控制方式,当QPS超过任意规则的阈值后,新的请求就会被立即拒绝,拒绝方式为抛出FlowException。这种方式适用于对系统处理能力确切已知的情况下,比如通过压测确定了系统的准确水位时。具体的例子参见 FlowqpsDemo。冷启动(RuleConstant.CONTROL_BEHAVIOR_WARM_UP)方式。该方式主要用于系统长期处于低水位的情况下,当流量突然增加时,直接把系统拉升到高水位可能瞬间把系统压垮。通过"冷启动",让通过的流量缓慢增加,在一定时间内逐渐增加到阈值上限,给冷系统一个预热的时间,避免冷系统被压垮的情况。具体的例子参见 WarmUpFlowDemo。匀速器(RuleConstant.CONTROL_BEHAVIOR_RATE_LIMITER)方式。这种方式严格控制了请求通过的间隔时间,也即是让请求以均匀的速度通过,对应的是漏桶算法。具体的例子参见 PaceFlowDemo。这种方式主要用于处理间隔性突发的流量,例如消息队列。想象一下这样的场景,在某一秒有大量的请求到来,而接下来的几秒则处于空闲状态,我们希望系统能够在接下来的空闲期间逐渐处理这些请求,而不是在第一秒直接拒绝多余的请求。
首先,对于上面这个分类我是存疑的,原因是这个分类把限流算法以及限流后的处理手段混为一谈了。比如第一种方式以
直接拒绝来命名,那么第二种冷启动的方式,超过qps之后,难道不是直接拒绝吗?不过,本篇我们重点讨论的是限流算法,暂时先忽略这些细节。先看看限流器的接口定义
TrafficShapingController,从它提供的能力来看,只是定义了请求是否能通过或被限流,并没有定义限流后的处理手段TrafficShapingController总共有4个实现类,除了官方文档里介绍的三个,还有一个RuleConstant.CONTROL_BEHAVIOR_WARM_UP_RATE_LIMITER。下面我们就逐一分析其实现原理
DefaultController
官方称为【直接拒绝】,不过从具体的实现上并看不出有“拒绝”的逻辑,被限流也只是返回false。拒绝那是上层的事情(虽然对false的场景,上层确实会处理成抛异常BlockException,从而拒绝请求。但是这对任何一个实现类都是一样的。)。另外,关于
DefaultController这个限流器的命名也令人匪夷所思,一般都应该按照其特点命名,即使要把它作为默认的TrafficShapingController实现类,也不应该直接用Default来命名啊,难道是官方无法准确的描述其特征吗?我们来看看它的具体实现:DefaultController的主逻辑很简单:根据限流的维度,从当前滑动窗口上的统计信息里取对应的统计值(qps或者并发数)。再结合本次请求需要获取的permits,来判断是否需要限流。主逻辑看完让我们再来看看分支逻辑,这个是所有的实现类里唯一使用到方法签名里
prioritized这个字段的地方。这段分支逻辑的含义是:当“高优”请求(prioritized=true)将要被限流时,可以提前锁定下一个时间窗口的permits(当然是下一个时间窗口没有被提前锁满的前提下),并阻塞等待到下个时间窗口即可放行。关于如何统计当前窗口上的请求数以及并发数,放到下一篇文章中再做分析。从这段“存在等待”的逻辑,官方描述的“直接拒绝”也是有失偏颇的。RateLimiterController 匀速器
RateLimiterController可以理解是基于漏桶算法的实现,主要保证稳定的请求通行频率。这是唯一没有使用到滑动窗口统计信息的限流器,完全是一套自成体系的限流。核心变量只有一个:
latestPassedTime,记录了最近一次请求通过的时间点。整个限流器都在保证按照1/count的速度来控制请求频率。每个请求进来都会根据本次需要获取的permits结合latestPassedTime算出能获取到这些permits的时间点,如果没到的话,就wait到这个时间点。另外还有一个maxQueueingTimeMs变量,可以理解为漏桶里最大的盛水量,超过之后就会拒绝。代码上比较简单,没有太多值得讲的地方。贴一张官方的示意图帮助理解: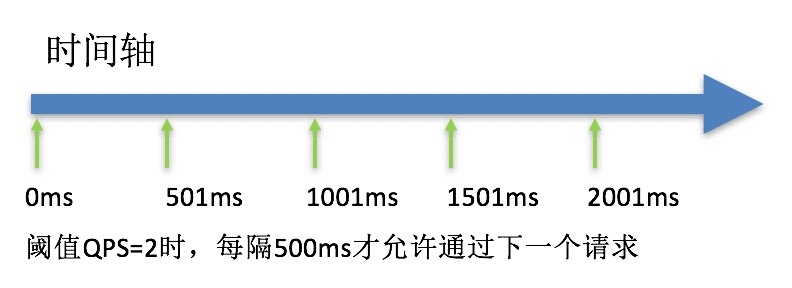
WarmUpController 预热
这可能是Sentinel里最复杂的一种限流器了。据
java doc描述它是基于Guava SmoothWarmingUp设计的,不过我整体看下来,感觉和前者还是有不少区别的。关于Guava SmoothWarmingUp的设计,你可以看我的另外一篇文章,里面有比较详细的分析。这类限流器通过增加一个预热期,防止应用长时间没有请求导致很多资源(比如数据库连接都回收了)都没准备好。也就是说,越长时间没请求,那限流器允许通过的qps就越低。我基于
Guava SmoothWarmingUp的图给WarmUpController也做了一张:关于这张图,我还是强烈推荐你先看这篇文章里关于Guava SmoothWarmingUp的图形分析。这里只说
WarmUpController的不同点:coldFactor默认值为3,但并非硬编码,我们可以调整它的值。而Guava的硬编码为3。
- 限定条件不同,本图限定
warmupPeriod/stablePeriod等于coldFactor - 1。而Guava的限定warmupPeriod=cooldownPeriod
虽然两者限定条件不同,但是说实话其中的数学原理我也不是非常理解,只能说尽可能的去理解作者的设计思路。我们只要知道,在限定条件下,能指导我们计算出warningToken以及maxToken的大小就可以了。
初始化预热参数
上图的代码表现如下,主要就是计算
warningToken、maxToken和斜率slop,通过上图里梯形、矩形的面积计算:预热的核心限流逻辑
初始化完成之后,我们再来看看判断是否限流的核心函数。逻辑结构还是比较清晰的:
- 根据当前时间和上次计算令牌的时间差补充
storedTokens
- 根据桶内的
storedTokens,结合上图来计算当时允许的qps
- 根据当前窗口已通过的qps来看此次请求是否被限流
storedTokens是怎么维护的
不过你仔细看了之后应该能发现它和Guava SmoothWarmingUp有个很大的区别:这里的请求通过之后并没有消耗storedTokens,它的值仅仅只是用来判断限流器忙闲程度的,但是既然不是通过请求消耗的,那又是怎么消耗的呢?
storedTokens的维护逻辑在syncToken和coolDownTokens方法里:填充逻辑
我们先看
storedTokens的填充逻辑,只有两个场景才会触发填充:- 之前的storedTokens小于warningToken
- 之前的storedTokens大于warningToken,但是上一个滑动子窗口的qps小于最冷时的qps
总感觉这块逻辑很诡异,也找不到任何的理论支撑,所以也只能研究到这里了。从测试结果来看,预热趋势肯定是有的,最终也能稳定在限定qps。
消耗逻辑
消耗逻辑也挺诡异的,为什么是减去前一个子窗口的请求数量?总感觉很不严谨。
WarmUpLimiterController 预热
这个和上面WarmUpController类似,唯一的区别是,当超过qps限制时,WarmUpLimiterController会wait到有“许可”,而不是直接拒绝。
总结
对于
WarmUpController花了不少时间去理解,但是还是不太理解其写法和设计,网上找了一些文章感觉也没有讲得很清楚的,多数也是表示不理解。希望有理解的大佬能指点一二。你应该注意到了,上面的4个限流器,其中3个都用到了
node.passQps()去获取当前窗口上统计的qps。Sentinel有自成一套的统计机制,我们将在下一篇文章中重点分析。参考
- Author:黑微狗
- URL:https://blog.hwgzhu.com/article/sentinel-rate-limiter-algo
- Copyright:All articles in this blog, except for special statements, adopt BY-NC-SA agreement. Please indicate the source!