type
status
date
slug
summary
tags
category
icon
password
AI summary
限流算法及常见实现
本篇文章总结了常见的限流算法,以及基于这些限流算法开发的靠谱的实现方案
指标维度
限流主要有两个指标维度,1个是qps,1个是并发数。qps和并发数的区别很容易理解,前者只考虑进,不考虑出,进来就消耗。而后者既考虑进也考虑出,进来增加,出去减少。举个简单的例子:
- qps:请求进来即消耗qps,10->9
- 并发量:请求进来即增加并发量,0->1,请求结束减少并发量,1->0
本篇文章不做特殊说明的话,均指qps维度的限流
常见的限流算法
固定窗口算法(Fixed Window)
把时间按照固定的长度划分为一个个的固定窗口,比如按照1分钟1个固定窗口拆分。请求进来之后会匹配到对应窗口,在窗口上计数,判断是否要限流。
缺点
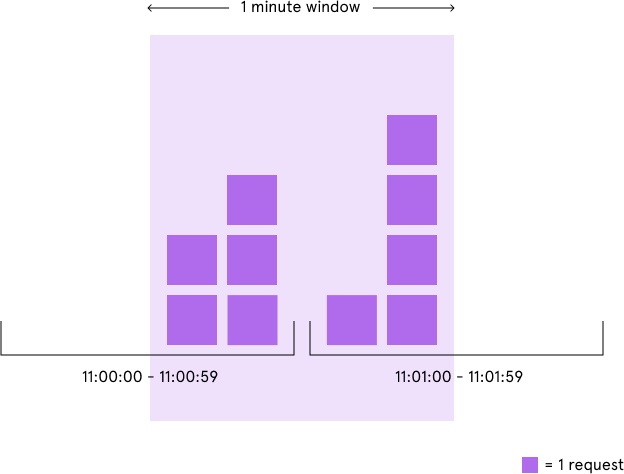
限流粒度较粗,容易发生临界突破限定qps的情况。如下图所示,我们的限流条件本来是每分钟5次,但是恶意用户在 11:00:00 ~ 11:00:59 这个时间窗口的后半分钟发起5次请求,接下来又在11:01:00~11:01:59这个时间窗口的前半分钟发起5次请求,这样我们的系统就在1分钟内承受了10次请求。(图片来源)
优点
逻辑简单,容易实现。如果把固定窗口的长度限定在1s甚至更小,理论上也能达到生产可用的标准。
典型实现
在单机场景下可以使用 AtomicLong、LongAdder 或 Semaphore 来实现计数。
而在分布式场景下可以通过以下两种Redis官方提供的方式实现:
这两种实现方案的固定窗口的时间长度均为1s,具体实现上略有差别:
- 方案1:key上带了时间戳信息
- 方案2:key上没时间戳,通过设置key的过期时间为1s
当然,我们也可以简单改造以支持不同的时间长度的窗口大小,比如我们想控制为1min
- 方案1:我们只需要调整key上的时间戳信息,去除秒级特征
- 方案2:我们只需要把key的过期时间设置为60s
滑动日志计数(Sliding Window Logs)
为了解决固定窗口算法的临界问题,我们可以把每次请求的时间节点都记录下来,那么只需要根据日志来统计指定窗口的请求数量就可以判断是否需要限流
优点
因为保存了每一次请求的日志,能统计任意时间范围,达到精准限流
缺点
- 存储开销大
- 实时统计请求数量可能有较大的计算开销
典型实现
下面介绍两种通过redis的sorted set来实现Sliding Window Logs的方案,按照时间维度统计的性能也较好。不过需要慎重考虑存储的问题,因为用户请求不可控。
这篇文章介绍了一种基于redis的sorted set实现的。它使用的命令序列为:
- 通过ZREMRANGEBYSCORE删除一个窗口之前的数据
- ZRANGE(0, -1)获取所有的请求日志
- ZADD把当前请求入队
- 设置key的ttl为一个窗口的时间长度(节约内存)
这4个命令被包裹在multi-exec里,执行完毕后,基于2中获取的请求日志进行代码层的判断,这里还可以一次性使用多个不同的限流规则(比如1min10次,1s3次,这里的最长时间窗决定了一个滑动窗口的大小)
这篇文章介绍的实现和上面的类似,但从文章看并没有在请求的时候去维护sorted set的长度,看起来是通过另外一个线程来维护的,不过这就增加了限流器的复杂度也带来了一些割裂感
这两种方式的区别有点像内存的手动回收和使用垃圾回收器回收。
滑动窗口计数(Sliding Window)
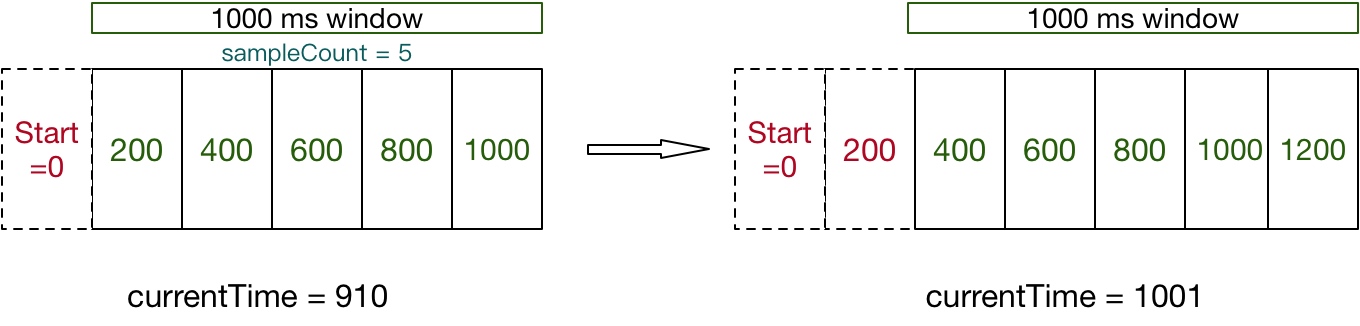
为了解决滑动日志对于存储的不可控性,于是又有了滑动窗口,它是根据请求进来的时间去往前框定一段时间窗口。由于时间窗口不固定,所以计数器应该维护到哪里呢?一般的做法会根据我们要限流的时间窗口拆分成更小的窗口用来滑动,拆分的越多精度越高,但是存储成本也越高。当拆分为1时,就退化成了固定窗口模式。
比如我们要按照1s维度做限流,这个时候可以拆分成5个200ms的小窗口,在请求进来的时候,我们就可以使用当前的窗口以及前4个窗口的数据汇总即可
缺点
相较于固定窗口和滑动日志,实现起来相对较复杂
优点
- 相较于固定窗口,能达到较精确的限流效果,避免短时间qps突破限制
- 相较于滑动日志,能大幅优化存储,把不可控变成可控
典型实现
sentinel里的实现
com.alibaba.csp.sentinel.slots.statistic.metric.BucketLeapArray漏桶
漏桶算法的核心是一个稳定的处理速度:流入不稳定,但是处理速度恒定,很像一个以一个恒定速度漏水的漏桶。但是从它的模型也不难看出,漏桶,无法攒水,只能往外漏水

缺点
无法应对突发流量,只能以一个固定的频率处理请求
典型实现
sentinel实现的匀速器就是基于漏桶算法
com.alibaba.csp.sentinel.slots.block.flow.controller.RateLimiterController令牌桶
为了应对突发流量,人们又发明了令牌桶算法(Token Bucket)。这种算法的核心思想是令牌可以积攒,通过积攒的令牌来应对突发流量。它是目前应用最广泛的一种限流算法,基本思想由两部分组成:生成令牌和消费令牌。
- 生成令牌:假设有一个装令牌的桶,最多能装M个,然后按某个固定的速度(每秒r个)往桶中放入令牌,桶满时不再放入;
- 消费令牌:我们的每次请求都需要从桶中拿N个令牌才能放行,当桶中没有令牌时即触发限流
优点
可以应对突发流量
缺点
需要在理解令牌桶算法的前提下配置合理的令牌桶相关参数,否则容易造成限流超过系统最大负载,影响稳定性。
典型实现
令牌桶算法一般会有两种不同的实现方式。
- 第一种方式是启动一个线程,不断的往桶中添加令牌,处理请求时从桶中获取令牌
- 第二种方式不依赖于内部线程,而是在每次处理请求之前先实时计算出要填充的令牌数并填充,然后再从桶中获取令牌
不过大多数实现都采用的是方式二,因为方式一增加了复杂度(引入了生产者,也带来了一些割裂感),并且实际应用过程中需要限流的key往往也难以枚举,比如按照用户id维度限流,那需要给每个用户准备一个令牌桶并不断往里添加令牌,所以方式一可行性较低
下面三种RateLimiter都是基于方式二实现的(链接都可点到相关文章):
限流的处理方式
当请求被限流规则拦截之后,一般有下面三种限流的处理方式:
- 拒绝服务
- 排队等待
- 服务降级
拒绝服务可以简单的返回http状态码429,也可以通过302重定向到某个页面进行一些真人验证。排队等待这种方式不常用,因为当需要排队的时候理论上已经超过系统的承载能力了,排队可能造成更大的压力,我们更倡导快速失败。服务降级的话,适用于一些非核心接口,我们可以直接返回默认值。
从这篇文章中我们看到了一种针对于特定场景的有意思的处理方式:由于返回429会让攻击者察觉而可能会通过更换账号等方式继续攻击,并且被攻击接口是一个操作类接口,攻击者无法从接口层面感知是否执行,所以被限流时继续返回200以迷惑攻击者。
警惕长窗口
无论采用哪种算法,都要避免时间窗口过长,举个例子:假设我们限定每个用户每1小时可以访问10000次。恶意用户可以在很短的时间内发送9999个请求,例如在10秒内,这相当于每秒100个请求,这可能会严重影响您的系统。一个熟练的攻击者可以停止在每小时9999个请求,并每小时重复一次,这将使这种攻击无法检测(因为不会达到限制)。为了防止这种攻击,您应该指定多个限制。比如10000次/小时、500次/分钟、10次/秒
总结
关于漏桶算法和令牌桶算法
从算法层面其实和容易区分两者的区别,但是在实现层面,漏桶算法很少有按照算法描述逻辑那样编码的。实现层面多是通过控制请求间隔频率来实现稳定漏水速度这一理念的。而这一理念用令牌桶的算法也是可以做到的,比如我让桶的大小为空,这个时候好像就退化成漏桶算法了。
参考
- Author:黑微狗
- URL:https://blog.hwgzhu.com/article/rate-limiter-algo-with-impl
- Copyright:All articles in this blog, except for special statements, adopt BY-NC-SA agreement. Please indicate the source!