type
status
date
slug
summary
tags
category
icon
password
AI summary
背景
在测试SpringBoot自带的
gzip压缩的过程中,发现min-response-size这个参数配置之后不生效。于是面向Google以及源代码来分析原因。min-response-size用来控制压缩阈值,不小于min-response-size的响应体才会被压缩源码分析基于
SpringBoot 2.3.4-RELEASE分析
SpringBoot的
gzip压缩并非自己实现,而是依赖于底层的web server。本文使用的web server是SpringBoot内嵌的tomcat。通过debug源代码定位到tomcat判断是否需要压缩响应体的代码段:可以看到,上面确实有对响应体大小和
min-response-size做比较。但是debug出来,contentLength始终等于-1,从而导致所有请求都需要压缩。那
Content-Length为什么会等于-1呢?主要是MappingJackson2HttpMessageConverter在写响应流的时候,会把Content-Length设置为null那为什么
MappingJackson2HttpMessageConverter不能设置Content-Length呢?我们通过阅读源代码来浅浅猜测一下:因为它直接边序列化响应对象边把结果写到响应体流里了,而并不是序列化完之后放在内存里。并且写响应流和获取响应体大小本身也是两个方法,并没有共享变量来通信,如果真要设置Content-Length的话,可能就需要多序列化一次。下面是
MappingJackson2HttpMessageConverter去序列化返回对象并写入响应体的代码,你可以感受一下:可以看到,整个流程还是挺复杂的,并且是直接序列化并写入到Response OutputStream里去了。这样的好处就是不需要额外占用内存空间保存序列化后的响应体。我们也找了一个设置了
Content-Length的Converter来看看,比如下面这个ObjectToStringHttpMessageConverter,可以看到,它其实就是做了两次转换,增加了性能损耗。Content-Length和Transfer-Encoding
那么没有
Content-Length的响应体,客户端如何知道什么时候读取完呢?Http协议里还有一个叫做Transfer-Encoding的Header。在最新的HTTP/1.1协议里,就只有
chunked这个参数,标识当前为分块编码传输。主要就是针对于未知大小的请求或者响应,传输时并不知道消息整体的大小,只管传输当前已经就绪的,在传输数据量较大的情况下,看起来就是一块一块的传输。而每块消息有固定的格式:- 每个分块包含一个 16 进制的数据长度值和真实数据。
- 数据长度值独占一行,和真实数据通过 CRLF(\r\n) 分割。
- 数据长度值,不计算真实数据末尾的 CRLF,只计算当前传输块的数据长度。
- 最后通过一个数据长度值为 0 的分块,来标记当前内容实体传输结束。
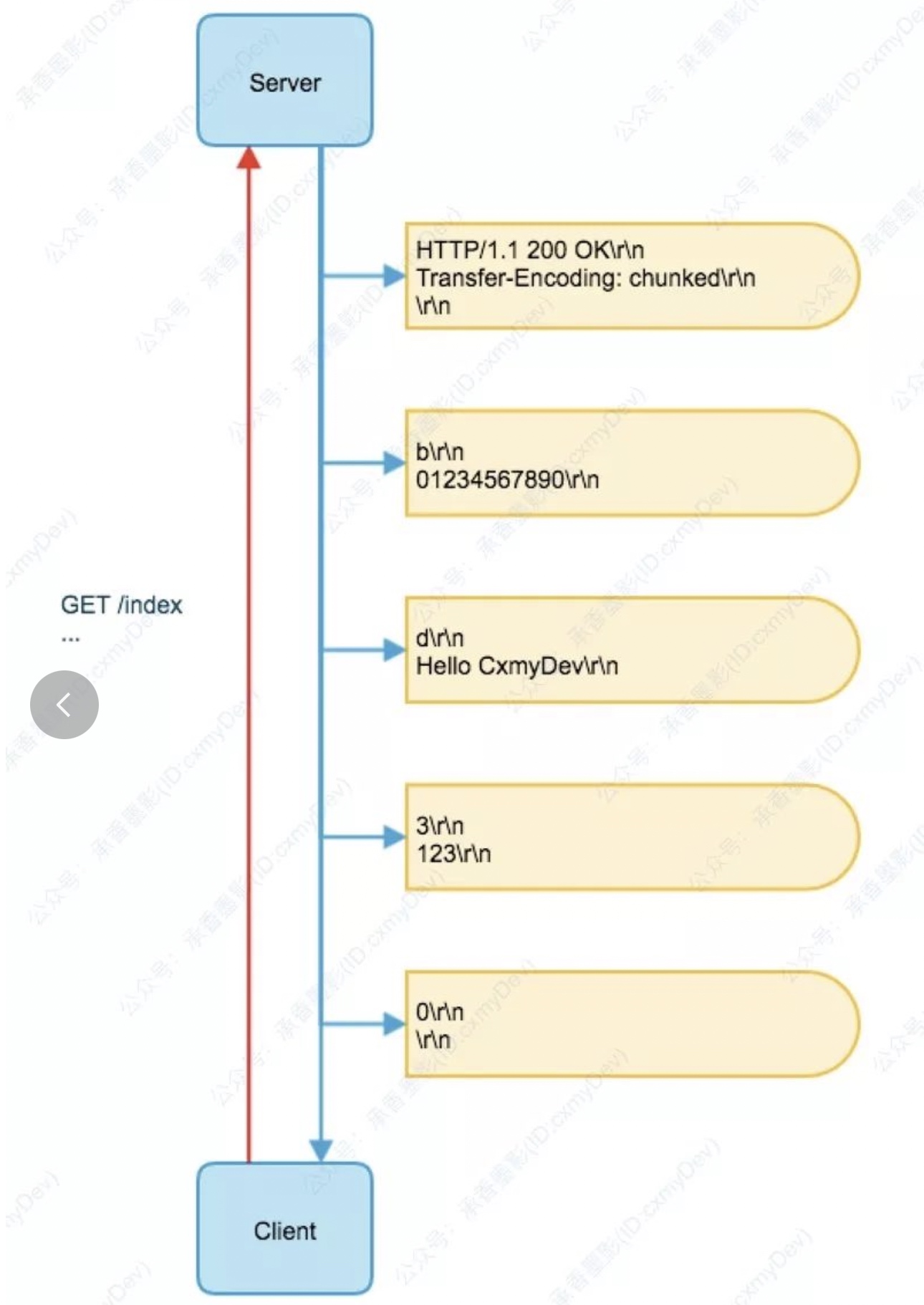
在这个例子中,首先在响应头部里标记了
Transfer-Encoding: chunked,后续先传递了第一个分块 “0123456780”,长度为 b(11 的十六进制),之后分别传输了 “Hello CxmyDev” 和 “123”,最后以一个长度为 0 的分块标记当前响应结束。分块传输编码的好处
下面的好处都是针对于持久连接来说的,非持久连接没有消息边界的问题,直接读到EOF就完事儿了。
- 允许服务器传输动态生成或者位置大小的内容,无需等待服务端全部读取完,可以边读取边传输或者是边生成边传输,提升了
TTFB(Time To First Byte,发出页面请求到接收到应答数据第一个字节的时间总和)
- 允许服务器在消息体后面发送额外的响应头字段(拖挂),这个非常重要当一个字段的值要等到响应内容全部产生后才能确定的情况下,如响应内容的数字签名,如果不使用分块传输服务器为了计算响应内容的算数字签名则必须先缓存所有内容直到内容产生完成。(如果不采用Chunked分块传输则在消息体后面发送的响应头不能被Recipient正确获取)。拖挂的响应头需要在前面用
Trailder头声明
- HTTP服务器有时使用compression(gzip或者deflate)方法优化传输即对被传输的字节进行压缩,chunked和gzip编码相互之间作用在HTTP编码的两个阶段;第一阶段响应内容字节流采用gzip进行压缩编码,压缩完成后产生的字节流采用chunked的方式进行传输编码,这意味着chunked和compression可以同时使用,只是作用于不同的阶段。
chunked请求抓包
Transfer-Encoding: chunked 既是响应头也能作为请求头,尤其是读取远程文件上传的场景。我们这里模拟了同一个GET请求分别使用
Transfer-Encoding: chunked和常规的Content-Length 来发起。通过抓包工具我们来看看两者的区别: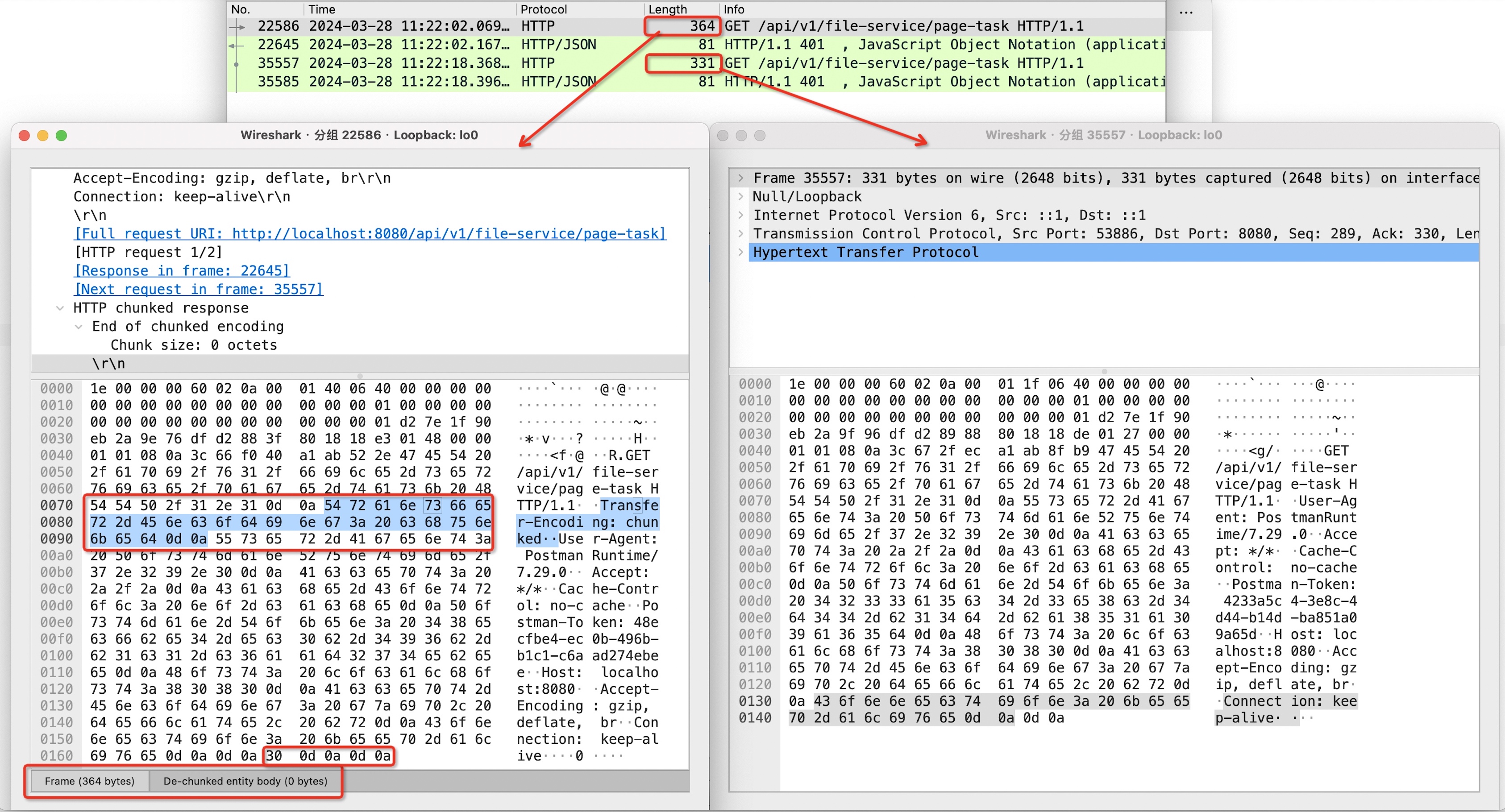
请求头增加
Transfer-Encoding: chunked参数之后,请求大小从331 bytes增加到了364 bytes,增加了33 bytes,其中:- 请求头增加了28 bytes。
Transfer-Encoding: chunked\r\n
- chunked块增加了5 bytes。因为我们是一个GET请求,没有请求体,所以chunked只增加了一个
0\r\n\r\n的结尾块。
解决方案
ShallowEtagHeaderFilter
这个方案是在Stackoverflow上看到的:通过在filter链里增加一个
ShallowEtagHeaderFilter。这个Filter的主要作用其实是处理http缓存里的协商缓存,Etag和If-None-Match。- 对于
Cache-Controller请求头,只要没有指定为no-store的请求,在成功响应后,ShallowEtagHeaderFilter会根据响应内容计算出Etag响应头,一同下发给客户端
- 客户端会保存对应的URL、Etag值以及响应内容到本地缓存中
- 当本地缓存过期后,客户端对于同个URL的请求会带上请求头
If-None-Match(值为上一次的ETag)请求服务器
ShallowEtagHeaderFilter会根据响应体计算Etag值,并和请求头的If-None-Match值进行对比,如果一致,则返回状态码304,告知客户端可以使用本地缓存,并刷新本地缓存时间。如果不一致就返回 200 响应并更新ETag的值
而
ShallowEtagHeaderFilter的实现是用一个Mock的OutputStream替换了真正的OutputStream,最终通过从Mock的OutputStream里把数据读取到内存并最终写入真正的响应流里。可以看到,这一步已经把响应体都读取出来了,自然就能拿到Content-Length 了。当然我们也可以自己写一个Filter,实现类似的逻辑即可。ShallowEtagHeaderFilter只能节省带宽,而不能提高服务器性能。如果对http缓存相应内容感兴趣的话,推荐阅读图解 HTTP 的缓存机制 | 实用 HTTP
修改MappingJackson2HttpMessageConverter代码
这个其实我们前面也有提到,相信你总有办法拿到序列化之后响应体的字节长度,就不展开说了。
不过这两种方案对性能应该都是有影响的,大家使用的时候还是需要斟酌一下并做好压测。
总结
Http作为使用最广泛的应用层协议,其内容、复杂度以及发展过程都值得细细的了解。每一次深度接触其实都会有一些新的启发。
其实本来只是因为压测碰到了带宽瓶颈所以想配置个压缩策略试试看效果,没想到引出这么多的内容。最终,其实我们并没有使用前面提到的两种方案。也没有在业务应用侧开启gzip压缩,而是把这项工作交给了我们基于spring-cloud-gateway二次开发的gateway。这个我们下一篇文章会详细再说。
参考
- Author:黑微狗
- URL:https://blog.hwgzhu.com/article/springboot-gzip-min-response-size-failed
- Copyright:All articles in this blog, except for special statements, adopt BY-NC-SA agreement. Please indicate the source!
Relate Posts