type
status
date
slug
summary
tags
category
icon
password
AI summary
HTTP缓存机制解析
引言
HTTP协议的缓存机制通常是由浏览器或其他HTTP客户端(例如okhttp、curl)来实现的。它主要涉及三种策略:存储策略、过期策略和协商策略。
- 存储策略:在接收到响应后,决定是否缓存响应内容。
- 过期策略:在发送请求前,判断缓存是否仍然有效。
- 协商策略:在请求过程中,由服务端判断缓存内容是否最新。
客户端在应用这些缓存策略时,会遵循如下判断流程:
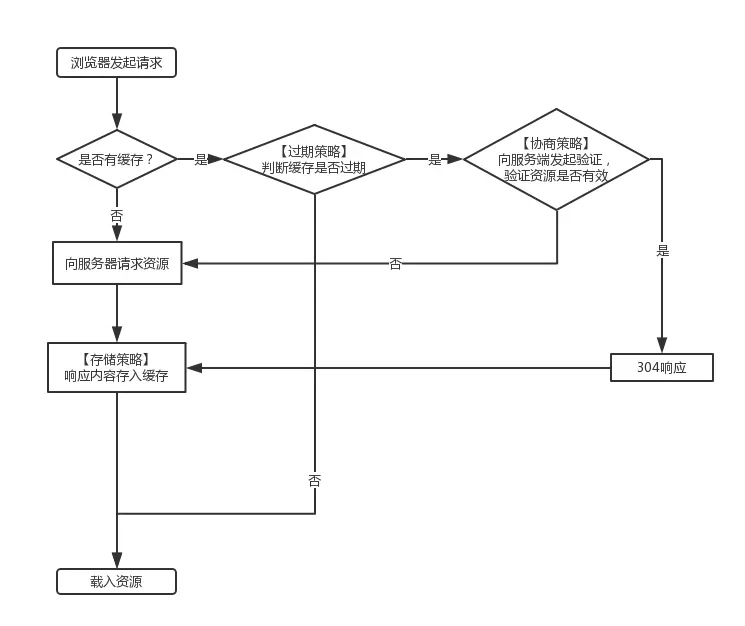
存储策略
存储策略用于确定HTTP响应内容是否可以被客户端缓存,以及可以被哪些客户端缓存。主要受
Cache-Control响应头影响。只有当Cache-Control的值为no-store时,客户端才不会缓存内容。其他值如public、private、no-cache、max-age,都表示客户端会缓存响应内容。- public:任何经过的节点都可以缓存(代理服务器也可缓存)
- private:只有发起请求的浏览器可以缓存
- no-cache:会缓存数据,但在使用前必须通过【协商策略】验证有效性,相当于max-age=0
成功存储到本地的缓存数据,并不意味着浏览器后续可以直接读取并使用。使用前还需要确定本地缓存的数据的有效性,这就是我们下面要讲到的【过期策略】。
过期策略
过期策略用于判断本地缓存是否过期。未过期的缓存数据可以直接使用,无需发起请求到服务端。
如何判断缓存是否过期?需要结合
Expires和Cache-Control这两个响应头。Expires是HTTP 1.0的响应头,表示这个响应结果的过期时间,是一个绝对时间,比如:Expires: Wed, 11 May 2018 07:20:00 GMT。不过绝对时间会存在一个问题,就是客户端和服务端的时间必须完全同步,这可能会带来一定的不可控性。HTTP 1.1增加了
Cache-Control响应头,并在里面增加了一个max-age属性,代表响应结果的相对有效时间,单位是秒,比如:Cache-Control: max-age=315360000,表示缓存有效期为10年。Expires和Cache-Control同时存在的话,后者的优先级更高。即使本地缓存已经过期,也不意味着缓存的数据就没用了。此时需要依靠”协商策略“联系服务端确认本地缓存内容的有效性。
协商策略
协商策略给过期的缓存增加了被重新激活的可能性。前面说到的缓存过期,都只是时间维度上的过期,并不代表它的内容过期。而协商策略就是客户端用来去服务端验证缓存的内容是否过期。验证的方式有两种:
- 通过对比两个响应的最后一次修改时间
- 通过对比两个响应的特征值
而这两个值都要依赖上一次请求结果的两个响应头——
Last-Modified和ETag。如果响应里没有下发这两个值,那后续的请求也无法走到协商策略。而对于存在这两个值的缓存数据,协商策略会在发起请求时添加两个对应的请求头——If-Modified-Since(对应Last-Modified)和If-None-Match (对应ETag),服务端会优先使用If-None-Match。对于
If-None-Match,如果它的值和服务端重新计算相应特征得到的值一样,或者对于If-Modified-Since,如果它和资源的最近修改时间一致,那么服务端就会下发304状态码,而不给具体的响应内容,告知客户端可以使用本地缓存。Last-Modified是HTTP 1.0的响应头,表示这个资源的最后更新时间。它的精度是秒级,如果出现1秒内多次修改同一个资源,那么在协商缓存阶段可能出现误判,导致使用了本地“脏”缓存。所以HTTP 1.1增加了Etag响应头,用来表示这个资源的特征值,只要内容变动Etag就会发生变化,精确度更高。但是由于Etag需要对资源提取资源特征,那就意味着要先获取资源并进行计算,所以从对服务端的性能消耗上来看,是比较大的。另外在分布式环境中,
Last-Modified 还可能会出现不同实例不一致的情况,而只要Hash算法一致Etag就可以保证一致性。启发式缓存
聊完上面三个策略之后,相信你对HTTP缓存应该已经有一个比较全面的了解了。下面我们再看看浏览器为了充分利用缓存设计的一个叫做“启发式缓存”的东西。
考虑我们在实际使用过程中,都没有刻意去加过
Cache-Control这个响应头。但是通过浏览器抓包,能看到很多js文件、css文件还是通过缓存加载的。这是什么原理呢?原来HTTP协议希望尽可能的缓存,即使响应头里没有
Cache-Control,如果满足某些条件,响应也会被存储和重用。这被称为启发式缓存。某些条件就是响应头里包含Last-Modified,这个时候浏览器会根据当前时间和Last-Modified的差值再除以10,得到一个缓存时间,在这段时间内的同一请求则会走到缓存。下面这张图可以比较好的理解cache-control不同取值的作用(最后一行ETag感觉有点格格不入~)

Vary
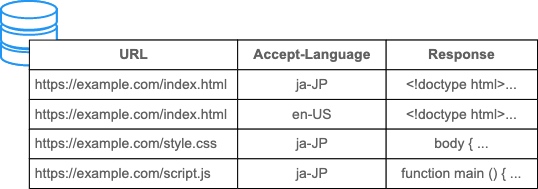
之前在研究跨域问题的时候还看到过一些这样的响应头,比如:
学习了HTTP缓存才知道这些响应头其实是为了缓存机制服务的:如果不加Vary头的话,缓存的key只有URL的维度。也就是说同一个URL,只能对应一份缓存。

但除了URL之外,有些Http头也会影响响应内容,尤其是在内容协商这一块,比如
Accept-Language和Accept-Encoding。如果说你的请求带了Accept-Language头,那么你需要再加上一个Vary头来表示它需要参与缓存Key的构建,加上之后缓存KEY也就增加了这个维度。
请求头里的Cache-Control
Cache-Control不仅出现在响应头中,也可以在请求头中使用。在请求头中,它指示本次请求应该如何使用缓存:- max-age=0:指示客户端不要使用缓存,但可以进行协商缓存。
- no-cache:指示客户端永远不要使用本地缓存。
访问页面的4种方式
地址栏回车、页面链接跳转、打开新窗口/标签页、history前进后退
这种方式会从过期策略开始判断,是用户浏览网页中最常用的方式。
点击刷新按钮、页面右键重新加载、f5、ctrl+R
这种方式会跳过过期策略,直接进入协商缓存。
但需要注意的是Initiator值为Other的内容才会走协商缓存(通常只有一个,是html内容)。其他的内容,因为是从html里引入的(如script,link,img等),或者从script文件动态引入的。他们的Initiator通常是一个html文件,或者script文件,这些资源还是会依照自己的规则,从过期策略开始判断;
这种方式会在请求头里添加Cache-Control:max-age=0,这是浏览器自己的行为
硬性重新加载、Ctrl+f5、Ctrl+Shift+R、勾选Disable cache后点刷新
这种方式,所有的资源(不论Initiator的值),都会跳过缓存判断,发起真实的请求,从服务端拿资源。但本地的缓存资源(如disk里的缓存)并没有删除。
这种方式会在请求头里添加Cache-Control:no-cache和Pragma: no-cache,也是浏览器自己的行为
清空缓存并硬性重新加载
这种方式,相当于先删除缓存(如disk里的缓存),再执行硬性重新加载
参考
- Author:黑微狗
- URL:https://blog.hwgzhu.com/article/http-cache
- Copyright:All articles in this blog, except for special statements, adopt BY-NC-SA agreement. Please indicate the source!